publications
2026
-
 Synthesizing scientific literature with retrieval-augmented language modelsAkari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, and 21 more authorsNature, Feb 2026AI for Science Domain Adaptation, Specialization, Generalization Retrieval-Augmented LMs Training Language Models
Synthesizing scientific literature with retrieval-augmented language modelsAkari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, and 21 more authorsNature, Feb 2026AI for Science Domain Adaptation, Specialization, Generalization Retrieval-Augmented LMs Training Language ModelsScientific progress depends on researchers’ ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar’s datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o’s correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o’s 32%. We open-source all of our code, models, datastore, data and a public demo.
@article{Asai2026OpenScholar, author = {Asai, Akari and He, Jacqueline and Shao, Rulin and Shi, Weijia and Singh, Amanpreet and Chang, Joseph Chee and Lo, Kyle and Soldaini, Luca and Feldman, Sergey and D'Arcy, Mike and Wadden, David and Latzke, Matt and Sparks, Jenna and Hwang, Jena D and Kishore, Varsha and Tian, Minyang and Ji, Pan and Liu, Shengyan and Tong, Hao and Wu, Bohao and Xiong, Yanyu and Zettlemoyer, Luke and Neubig, Graham and Weld, Daniel S and Downey, Doug and Yih, Wen-tau and Koh, Pang Wei and Hajishirzi, Hannaneh}, doi = {10.1038/s41586-025-10072-4}, journal = {Nature}, month = feb, title = {Synthesizing scientific literature with retrieval-augmented language models}, url = {https://www.nature.com/articles/s41586-025-10072-4}, volume = {650}, year = {2026} } -
 A Human-Centric Framework for Data Attribution in Large Language ModelsAmelie Wührl, Mattes Ruckdeschel, Kyle Lo, and Anna RogersArXiv, Feb 2026
A Human-Centric Framework for Data Attribution in Large Language ModelsAmelie Wührl, Mattes Ruckdeschel, Kyle Lo, and Anna RogersArXiv, Feb 2026In the current Large Language Model (LLM) ecosystem, creators have little agency over how their data is used, and LLM users may find themselves unknowingly plagiarizing existing sources. Attribution of LLM-generated text to LLM input data could help with these challenges, but so far we have more questions than answers: what elements of LLM outputs require attribution, what goals should it serve, how should it be implemented? We contribute a human-centric data attribution framework, which situates the attribution problem within the broader data economy. Specific use cases for attribution, such as creative writing assistance or fact-checking, can be specified via a set of parameters (including stakeholder objectives and implementation criteria). These criteria are up for negotiation by the relevant stakeholder groups: creators, LLM users, and their intermediaries (publishers, platforms, AI companies). The outcome of domain-specific negotiations can be implemented and tested for whether the stakeholder goals are achieved. The proposed approach provides a bridge between methodological NLP work on data attribution, governance work on policy interventions, and economic analysis of creator incentives for a sustainable equilibrium in the data economy.
@article{Whrl2026HumancentricFramework, author = {Wührl, Amelie and Ruckdeschel, Mattes and Lo, Kyle and Rogers, Anna}, journal = {ArXiv}, month = feb, title = {A Human-Centric Framework for Data Attribution in Large Language Models}, url = {https://arxiv.org/abs/2602.10995}, volume = {2602.10995}, year = {2026} } -
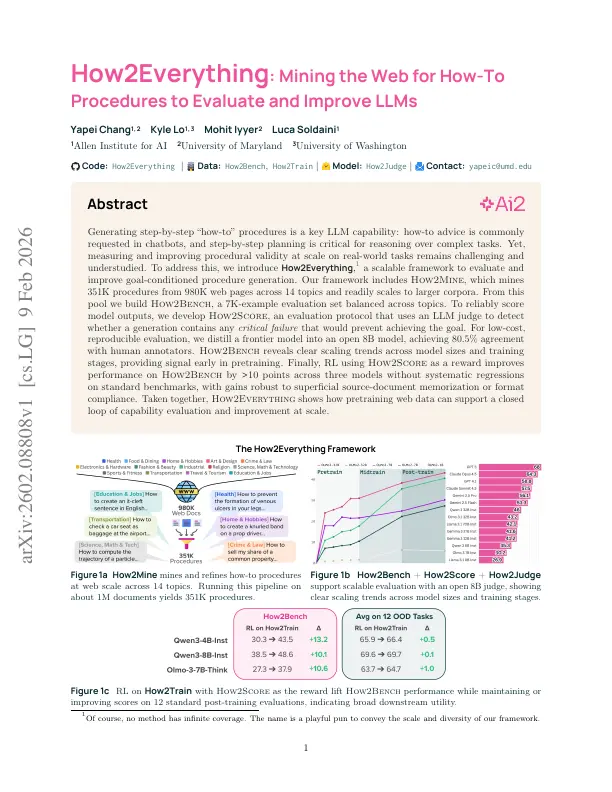 How2Everything: Mining the Web for How-To Procedures to Evaluate and Improve LLMsYapei Chang, Kyle Lo, Mohit Iyyer, and Luca SoldainiArXiv, Feb 2026
How2Everything: Mining the Web for How-To Procedures to Evaluate and Improve LLMsYapei Chang, Kyle Lo, Mohit Iyyer, and Luca SoldainiArXiv, Feb 2026Generating step-by-step "how-to" procedures is a key LLM capability: how-to advice is commonly requested in chatbots, and step-by-step planning is critical for reasoning over complex tasks. Yet, measuring and improving procedural validity at scale on real-world tasks remains challenging and understudied. To address this, we introduce How2Everything, a scalable framework to evaluate and improve goal-conditioned procedure generation. Our framework includes How2Mine, which mines 351K procedures from 980K web pages across 14 topics and readily scales to larger corpora. From this pool we build How2Bench, a 7K-example evaluation set balanced across topics. To reliably score model outputs, we develop How2Score, an evaluation protocol that uses an LLM judge to detect whether a generation contains any critical failure that would prevent achieving the goal. For low-cost, reproducible evaluation, we distill a frontier model into an open 8B model, achieving 80.5% agreement with human annotators. How2Bench reveals clear scaling trends across model sizes and training stages, providing signal early in pretraining. Finally, RL using How2Score as a reward improves performance on How2Bench by >10 points across three models without systematic regressions on standard benchmarks, with gains robust to superficial source-document memorization or format compliance. Taken together, How2Everything shows how pretraining web data can support a closed loop of capability evaluation and improvement at scale.
@article{Chang2026How2everythingMining, author = {Chang, Yapei and Lo, Kyle and Iyyer, Mohit and Soldaini, Luca}, journal = {ArXiv}, month = feb, title = {How2Everything: Mining the Web for How-To Procedures to Evaluate and Improve LLMs}, url = {https://arxiv.org/abs/2602.08808}, volume = {2602.08808}, year = {2026} } -
 Olmix: A Framework for Data Mixing Throughout LM DevelopmentMayee F Chen, Tyler Murray, David Heineman, Matt Jordan, Hannaneh Hajishirzi, Christopher Ré, Luca Soldaini, and 1 more authorArXiv, Feb 2026
Olmix: A Framework for Data Mixing Throughout LM DevelopmentMayee F Chen, Tyler Murray, David Heineman, Matt Jordan, Hannaneh Hajishirzi, Christopher Ré, Luca Soldaini, and 1 more authorArXiv, Feb 2026Data mixing – determining the ratios of data from different domains – is a first-order concern for training language models (LMs). While existing mixing methods show promise, they fall short when applied during real-world LM development. We present Olmix, a framework that addresses two such challenges. First, the configuration space for developing a mixing method is not well understood – design choices across existing methods lack justification or consensus and overlook practical issues like data constraints. We conduct a comprehensive empirical study of this space, identifying which design choices lead to a strong mixing method. Second, in practice, the domain set evolves throughout LM development as datasets are added, removed, partitioned, and revised – a problem setting largely unaddressed by existing works, which assume fixed domains. We study how to efficiently recompute the mixture after the domain set is updated, leveraging information from past mixtures. We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update. Over a sequence of five domain-set updates mirroring real-world LM development, mixture reuse matches the performance of fully recomputing the mix after each update with 74% less compute and improves over training without mixing by 11.6% on downstream tasks.
@article{Chen2026OlmixFramework, author = {Chen, Mayee F and Murray, Tyler and Heineman, David and Jordan, Matt and Hajishirzi, Hannaneh and Ré, Christopher and Soldaini, Luca and Lo, Kyle}, journal = {ArXiv}, month = feb, title = {Olmix: A Framework for Data Mixing Throughout LM Development}, url = {https://arxiv.org/abs/2602.12237}, volume = {2602.12237}, year = {2026} }




2025
-
 Signal and noise: A framework for reducing uncertainty in language model evaluationDavid Heineman, Valentin Hofmann, Ian Magnusson, Yuling Gu, Noah A Smith, Hannaneh Hajishirzi, Kyle Lo, and 1 more authorIn NeurIPS (Datasets and Benchmarks), Dec 2025
Signal and noise: A framework for reducing uncertainty in language model evaluationDavid Heineman, Valentin Hofmann, Ian Magnusson, Yuling Gu, Noah A Smith, Hannaneh Hajishirzi, Kyle Lo, and 1 more authorIn NeurIPS (Datasets and Benchmarks), Dec 2025Developing large language models is expensive and involves making decisions with small experiments, typically by evaluating on large, multi-task evaluation suites. In this work, we analyze specific properties which make a benchmark more reliable for such decisions, and interventions to design higher-quality evaluation benchmarks. We introduce two key metrics that show differences in current benchmarks: signal, a benchmark’s ability to separate better models from worse models, and noise, a benchmark’s sensitivity to random variability between training steps. We demonstrate that benchmarks with a better signal-to-noise ratio are more reliable when making decisions at small scale, and those with less noise have lower scaling law prediction error. These results suggest that improving signal or noise will lead to more useful benchmarks, so we introduce three interventions designed to directly affect signal or noise. For example, we propose that switching to a metric that has better signal and noise (e.g., perplexity rather than accuracy) leads to better reliability and improved scaling law error. We also find that filtering noisy subtasks, to improve an aggregate signal-to-noise ratio, leads to more reliable multi-task evaluations. We also find that averaging the output of a model’s intermediate checkpoints to reduce noise leads to consistent improvements. We conclude by recommending that those creating new benchmarks, or selecting which existing benchmarks to use, aim for high signal and low noise. We use 30 benchmarks for these experiments, and 375 open-weight language models from 60M to 32B parameters, resulting in a new, publicly available dataset of 900K evaluation benchmark results, totaling 200M instances.
@inproceedings{Heineman2025SignalAndNoise, author = {Heineman, David and Hofmann, Valentin and Magnusson, Ian and Gu, Yuling and Smith, Noah A and Hajishirzi, Hannaneh and Lo, Kyle and Dodge, Jesse}, booktitle = {NeurIPS (Datasets and Benchmarks)}, month = dec, title = {Signal and noise: A framework for reducing uncertainty in language model evaluation}, url = {https://arxiv.org/abs/2508.13144}, year = {2025} } -
 FlexOlmo: Open Language Models for Flexible Data UseWeijia Shi, Akshita Bhagia, Kevin Farhat, Niklas Muennighoff, Pete Walsh, Jacob Morrison, Dustin Schwenk, and 16 more authorsIn NeurIPS, Dec 2025
FlexOlmo: Open Language Models for Flexible Data UseWeijia Shi, Akshita Bhagia, Kevin Farhat, Niklas Muennighoff, Pete Walsh, Jacob Morrison, Dustin Schwenk, and 16 more authorsIn NeurIPS, Dec 2025We introduce FlexOlmo, a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets. We evaluate models with up to 37 billion parameters (20 billion active) on 31 diverse downstream tasks. We show that a general expert trained on public data can be effectively combined with independently trained experts from other data owners, leading to an average 41% relative improvement while allowing users to opt out of certain data based on data licensing or permission requirements. Our approach also outperforms prior model merging methods by 10.1% on average and surpasses the standard MoE trained without data restrictions using the same training FLOPs. Altogether, this research presents a solution for both data owners and researchers in regulated industries with sensitive or protected data. FlexOlmo enables benefiting from closed data while respecting data owners’ preferences by keeping their data local and supporting fine-grained control of data access during inference.
@inproceedings{Shi2025FlexolmoOpenLanguage, author = {Shi, Weijia and Bhagia, Akshita and Farhat, Kevin and Muennighoff, Niklas and Walsh, Pete and Morrison, Jacob and Schwenk, Dustin and Longpre, Shayne and Poznanski, Jake and Ettinger, Allyson and Liu, Daogao and Li, Margaret and Groeneveld, Dirk and Lewis, Mike and Yih, Wen-tau and Soldaini, Luca and Lo, Kyle and Smith, Noah A and Zettlemoyer, Luke and Koh, Pang Wei and Hajishirzi, Hannaneh and Farhadi, Ali and Min, Sewon}, booktitle = {NeurIPS}, month = dec, title = {FlexOlmo: Open Language Models for Flexible Data Use}, url = {https://openreview.net/forum?id=1rUj9ZN6Bz}, year = {2025} } -
 Olmo 3Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, and 61 more authorsArXiv, Dec 2025
Olmo 3Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, and 61 more authorsArXiv, Dec 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
@article{Olmo2025Olmo3, author = {Olmo, Team and Ettinger, Allyson and Bertsch, Amanda and Kuehl, Bailey and Graham, David and Heineman, David and Groeneveld, Dirk and Brahman, Faeze and Timbers, Finbarr and Ivison, Hamish and Morrison, Jacob and Poznanski, Jake and Lo, Kyle and Soldaini, Luca and Jordan, Matt and Chen, Mayee and Noukhovitch, Michael and Lambert, Nathan and Walsh, Pete and Dasigi, Pradeep and Berry, Robert and Malik, Saumya and Shah, Saurabh and Geng, Scott and Arora, Shane and Gupta, Shashank and Anderson, Taira and Xiao, Teng and Murray, Tyler and Romero, Tyler and Graf, Victoria and Asai, Akari and Bhagia, Akshita and Wettig, Alexander and Liu, Alisa and Rangapur, Aman and Anastasiades, Chloe and Huang, Costa and Schwenk, Dustin and Trivedi, Harsh and Magnusson, Ian and Lochner, Jaron and Liu, Jiacheng and Miranda, Lester James V and Sap, Maarten and Morgan, Malia and Schmitz, Michael and Guerquin, Michal and Wilson, Michael and Huff, Regan and Bras, Ronan Le and Xin, Rui and Shao, Rulin and Skjonsberg, Sam and Shen, Shannon Zejiang and Li, Shuyue Stella and Wilde, Tucker and Pyatkin, Valentina and Merrill, Will and Chang, Yapei and Gu, Yuling and Zeng, Zhiyuan and Sabharwal, Ashish and Zettlemoyer, Luke and Koh, Pang Wei and Farhadi, Ali and Smith, Noah A and Hajishirzi, Hannaneh}, journal = {ArXiv}, month = dec, cv_authors_after = {Team Olmo}, cv_authors_before = {Team Olmo}, title = {Olmo 3}, url = {https://arxiv.org/abs/2512.13961}, volume = {2512.13961}, year = {2025} } -
 Fluid language model benchmarkingValentin Hofmann, David Heineman, Ian Magnusson, Kyle Lo, Jesse Dodge, Maarten Sap, Pang Wei Koh, and 3 more authorsIn COLM, Oct 2025
Fluid language model benchmarkingValentin Hofmann, David Heineman, Ian Magnusson, Kyle Lo, Jesse Dodge, Maarten Sap, Pang Wei Koh, and 3 more authorsIn COLM, Oct 2025Language model (LM) benchmarking faces several challenges: comprehensive evaluations are costly, benchmarks often fail to measure the intended capabilities, and evaluation quality can degrade due to labeling errors and benchmark saturation. Although various strategies have been proposed to mitigate these issues, they tend to address individual aspects in isolation, neglecting broader questions about overall evaluation quality. Here, we introduce Fluid Benchmarking, a new evaluation approach that advances LM benchmarking across multiple dimensions. Inspired by psychometrics, Fluid Benchmarking is based on the insight that the relative value of benchmark items depends on an LM’s capability level, suggesting that evaluation should adapt to each LM. Methodologically, Fluid Benchmarking estimates an item response model based on existing LM evaluation results and uses the inferred quantities to select evaluation items dynamically, similar to computerized adaptive testing in education. In our experiments, we compare Fluid Benchmarking against the common practice of random item sampling as well as more sophisticated baselines, including alternative methods grounded in item response theory. We examine four dimensions – efficiency, validity, variance, and saturation – and find that Fluid Benchmarking achieves superior performance in all of them (e.g., higher validity and less variance on MMLU with fifty times fewer items). Our analysis shows that the two components of Fluid Benchmarking have distinct effects: item response theory, used to map performance into a latent ability space, increases validity, while dynamic item selection reduces variance. Overall, our results suggest that LM benchmarking can be substantially improved by moving beyond static evaluation.
@inproceedings{Hofmann2025FluidLanguageModel, author = {Hofmann, Valentin and Heineman, David and Magnusson, Ian and Lo, Kyle and Dodge, Jesse and Sap, Maarten and Koh, Pang Wei and Wang, Chun and Hajishirzi, Hannaneh and Smith, Noah A}, booktitle = {COLM}, month = oct, title = {Fluid language model benchmarking}, url = {https://arxiv.org/abs/2509.11106}, year = {2025} } -
 LLMs as Research Tools: A Large Scale Survey of Researchers’ Usage and PerceptionsZhehui Liao, Maria Antoniak, Inyoung Cheong, Evie Yu-Yen Cheng, Ai-Heng Lee, Kyle Lo, Joseph Chee Chang, and 1 more authorIn COLM, Oct 2025
LLMs as Research Tools: A Large Scale Survey of Researchers’ Usage and PerceptionsZhehui Liao, Maria Antoniak, Inyoung Cheong, Evie Yu-Yen Cheng, Ai-Heng Lee, Kyle Lo, Joseph Chee Chang, and 1 more authorIn COLM, Oct 2025The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipeline, while others have urged caution due to risks and ethical concerns. Yet little work has sought to quantify and characterize how researchers use LLMs and why. We present the first large-scale survey of 816 verified research article authors to understand how the research community leverages and perceives LLMs as research tools. We examine participants’ self-reported LLM usage, finding that 81% of researchers have already incorporated LLMs into different aspects of their research workflow. We also find that traditionally disadvantaged groups in academia (non-White, junior, and non-native English speaking researchers) report higher LLM usage and perceived benefits, suggesting potential for improved research equity. However, women, non-binary, and senior researchers have greater ethical concerns, potentially hindering adoption.
@inproceedings{Liao2024LlmsAsResearch, author = {Liao, Zhehui and Antoniak, Maria and Cheong, Inyoung and Cheng, Evie Yu-Yen and Lee, Ai-Heng and Lo, Kyle and Chang, Joseph Chee and Zhang, Amy X}, booktitle = {COLM}, month = oct, title = {LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions}, url = {https://arxiv.org/abs/2411.05025}, year = {2025} } -
 olmOCR 2: Unit Test Rewards for Document OCRJake Poznanski, Luca Soldaini, and Kyle LoArXiv, Oct 2025
olmOCR 2: Unit Test Rewards for Document OCRJake Poznanski, Luca Soldaini, and Kyle LoArXiv, Oct 2025We present olmOCR 2, the latest in our family of powerful OCR systems for converting digitized print documents, like PDFs, into clean, naturally ordered plain text. olmOCR 2 is powered by olmOCR-2-7B-1025, a specialized, 7B vision language model (VLM) trained using reinforcement learning with verifiable rewards (RLVR), where our rewards are a diverse set of binary unit tests. To scale unit test creation, we develop a pipeline for generating synthetic documents with diverse and challenging layouts, known ground-truth HTML source code, and extracted test cases. We show that RL training on these test cases results in state-of-the-art performance on olmOCR-Bench, our English-language OCR benchmark, with the largest improvements in math formula conversion, table parsing, and multi-column layouts compared to previous versions. We release our model, data and code under permissive open licenses.
@article{Poznanski2025OlmocrUnit, author = {Poznanski, Jake and Soldaini, Luca and Lo, Kyle}, journal = {ArXiv}, month = oct, title = {olmOCR 2: Unit Test Rewards for Document OCR}, url = {https://arxiv.org/abs/2510.19817}, volume = {2510.19817}, year = {2025} } -
 Contextualized evaluations: Judging language model responses to underspecified queriesChaitanya Malaviya, Joseph Chee Chang, Dan Roth, Mohit Iyyer, Mark Yatskar, and Kyle LoTransactions of ACL (TACL), Jul 2025
Contextualized evaluations: Judging language model responses to underspecified queriesChaitanya Malaviya, Joseph Chee Chang, Dan Roth, Mohit Iyyer, Mark Yatskar, and Kyle LoTransactions of ACL (TACL), Jul 2025Language model users often issue queries that lack specification, where the context under which a query was issued – such as the user’s identity, the query’s intent, and the criteria for a response to be useful – is not explicit. For instance, a good response to a subjective query like “What book should I read next?” would depend on the user’s preferences, and a good response to an open-ended query like “How do antibiotics work against bacteria?” would depend on the user’s expertise. This makes evaluation of responses to such queries an ill-posed task, as evaluators may make arbitrary judgments about the response quality. To remedy this, we present contextualized evaluations, a protocol that synthetically constructs context surrounding an underspecified query and provides it during evaluation. We find that the presence of context can 1) alter conclusions drawn from evaluation, even flipping benchmark rankings between model pairs, 2) nudge evaluators to make fewer judgments based on surface-level criteria, like style, and 3) provide new insights about model behavior across diverse contexts. Specifically, our procedure suggests a potential bias towards WEIRD (Western, Educated, Industrialized, Rich and Democratic) contexts in models’ “default” responses and we find that models are not equally sensitive to following different contexts, even when they are provided in prompts.
@article{Malaviya2025ContextualizedEvaluationsJudging, author = {Malaviya, Chaitanya and Chang, Joseph Chee and Roth, Dan and Iyyer, Mohit and Yatskar, Mark and Lo, Kyle}, doi = {10.1162/TACL.a.24}, journal = {Transactions of ACL (TACL)}, month = jul, title = {Contextualized evaluations: Judging language model responses to underspecified queries}, url = {https://direct.mit.edu/tacl/article/doi/10.1162/TACL.a.24/132120/}, volume = {13}, year = {2025} } -
 Organize the Web: Constructing Domains Enhances Pre-Training Data CurationAlexander Wettig, Kyle Lo, Sewon Min, Hannaneh Hajishirzi, Danqi Chen, and Luca SoldainiIn ICML, Jul 2025
Organize the Web: Constructing Domains Enhances Pre-Training Data CurationAlexander Wettig, Kyle Lo, Sewon Min, Hannaneh Hajishirzi, Danqi Chen, and Luca SoldainiIn ICML, Jul 2025Modern language models are trained on large, unstructured datasets consisting of trillions of tokens and obtained by crawling the web. The unstructured nature makes it difficult to reason about their contents and develop systematic approaches to data curation. In this paper, we unpack monolithic web corpora by developing taxonomies of their contents and organizing them into domains. We introduce WebOrganizer, a framework for organizing web pages in terms of both their topic and format. Using these two complementary notions of domains, we automatically annotate pre-training data by distilling annotations from a large language model into efficient classifiers. This allows us to study how data from different domains should be mixed to improve models on downstream tasks, and we show that we can combine insights about effective topics and formats to further boost performance. We demonstrate that our domain mixing also improves existing methods that select data based on quality. Furthermore, we study and compare how quality-based methods will implicitly change the domain mixture. Overall, our work demonstrates that constructing and mixing domains provides a valuable complement to quality-based data curation methods, opening new avenues for effective and insightful pre-training data curation.
@inproceedings{Wettig2025OrganizeWeb, author = {Wettig, Alexander and Lo, Kyle and Min, Sewon and Hajishirzi, Hannaneh and Chen, Danqi and Soldaini, Luca}, booktitle = {ICML}, month = jul, title = {Organize the Web: Constructing Domains Enhances Pre-Training Data Curation}, url = {https://openreview.net/forum?id=boSqwdvJVC}, year = {2025} } -
 Human-AI Collaboration: How AIs Augment Human TeammatesSherry Wu, Diyi Yang, Joseph Z Chang, Marti A Hearst, and Kyle LoIn ACL, Jul 2025
Human-AI Collaboration: How AIs Augment Human TeammatesSherry Wu, Diyi Yang, Joseph Z Chang, Marti A Hearst, and Kyle LoIn ACL, Jul 2025The continuous, rapid development of general-purpose models like LLMs suggests the theoretical possibility of AI performing any human task. Yet, despite the potential and promise, these models are far from perfect, excelling at certain tasks while struggling with others. The tension between what is possible and a model’s limitations raises the general research question that has attracted attention from various disciplines: What is the best way to use AI to maximize its benefits? In this tutorial, we will review recent developments related to human-AI teaming and collaboration. To the best of our knowledge, our tutorial will be the first to provide a more integrated view from NLP, HCI, Computational Social Science, and Learning Science, etc., and highlight how different communities have identified the goals and societal impacts of such collaborations, both positive and negative. We will further discuss how to operationalize these Human-AI collaboration goals, and reflect on how state-of-the-art AI models should be evaluated and scaffolded to make them most useful in collaborative contexts.
@inproceedings{Wu2025HumanaiCollaborationHow, author = {Wu, Sherry and Yang, Diyi and Chang, Joseph Z and Hearst, Marti A and Lo, Kyle}, booktitle = {ACL}, doi = {10.18653/v1/2025.acl-tutorials.4}, month = jul, needs_review = {true}, title = {Human-AI Collaboration: How AIs Augment Human Teammates}, url = {https://aclanthology.org/2025.acl-tutorials.4/}, year = {2025} } -
 Setting The Table with Intent: Intent-aware Schema Generation and Editing for Literature Review TablesVishakh Padmakumar, Joseph Chee Chang, Kyle Lo, Doug Downey, and Aakanksha NaikArXiv, Jul 2025
Setting The Table with Intent: Intent-aware Schema Generation and Editing for Literature Review TablesVishakh Padmakumar, Joseph Chee Chang, Kyle Lo, Doug Downey, and Aakanksha NaikArXiv, Jul 2025The increasing volume of academic literature makes it essential for researchers to organize, compare, and contrast collections of documents. Large language models (LLMs) can support this process by generating schemas defining shared aspects along which to compare papers. However, progress on schema generation has been slow due to: (i) ambiguity in reference-based evaluations, and (ii) lack of editing/refinement methods. Our work is the first to address both issues. First, we present an approach for augmenting unannotated table corpora with synthesized intents, and apply it to create a dataset for studying schema generation conditioned on a given information need, thus reducing ambiguity. With this dataset, we show how incorporating table intents significantly improves baseline performance in reconstructing reference schemas. We start by comprehensively benchmarking several single-shot schema generation methods, including prompted LLM workflows and fine-tuned models, showing that smaller, open-weight models can be fine-tuned to be competitive with state-of-the-art prompted LLMs. Next, we propose several LLM-based schema refinement techniques and show that these can further improve schemas generated by these methods.
@article{Padmakumar2025SettingTable, author = {Padmakumar, Vishakh and Chang, Joseph Chee and Lo, Kyle and Downey, Doug and Naik, Aakanksha}, journal = {ArXiv}, month = jul, title = {Setting The Table with Intent: Intent-aware Schema Generation and Editing for Literature Review Tables}, url = {https://ui.adsabs.harvard.edu/abs/2025arXiv250719521P/abstract}, volume = {2507.19521}, year = {2025} } -
 Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language ModelsMatt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, and 43 more authorsIn CVPR, Jun 2025
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language ModelsMatt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, and 43 more authorsIn CVPR, Jun 2025Best Paper Honorable Mention
Today’s most advanced vision-language models (VLMs) remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed VLMs into open ones. As a result, the community has been missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key contribution is a collection of new datasets called PixMo, including a dataset of highly detailed image captions for pre-training, a free-form image Q&A dataset for fine-tuning, and an innovative 2D pointing dataset, all collected without the use of external VLMs. The success of our approach relies on careful modeling choices, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets. Our best-in-class 72B model not only outperforms others in the class of open weight and data models, but also outperforms larger proprietary models including Claude 3.5 Sonnet, and Gemini 1.5 Pro and Flash, second only to GPT-4o based on both academic benchmarks and on a large human evaluation. Our model weights, new datasets, and source code are available at https://molmo.allenai.org/blog.
@inproceedings{Deitke2025MolmoAndPixmo, author = {Deitke, Matt and Clark, Christopher and Lee, Sangho and Tripathi, Rohun and Yang, Yue and Park, Jae Sung and Salehi, Mohammadreza and Muennighoff, Niklas and Lo, Kyle and Soldaini, Luca and Lu, Jiasen and Anderson, Taira and Bransom, Erin and Ehsani, Kiana and Ngo, Huong and Chen, YenSung and Patel, Ajay and Yatskar, Mark and Callison-Burch, Chris and Head, Andrew and Hendrix, Rose and Bastani, Favyen and VanderBilt, Eli and Lambert, Nathan and Chou, Yvonne and Chheda, Arnavi and Sparks, Jenna and Skjonsberg, Sam and Schmitz, Michael and Sarnat, Aaron and Bischoff, Byron and Walsh, Pete and Newell, Chris and Wolters, Piper and Gupta, Tanmay and Zeng, Kuo-Hao and Borchardt, Jon and Groeneveld, Dirk and Nam, Crystal and Lebrecht, Sophie and Wittlif, Caitlin and Schoenick, Carissa and Michel, Oscar and Krishna, Ranjay and Weihs, Luca and Smith, Noah A and Hajishirzi, Hannaneh and Girshick, Ross and Farhadi, Ali and Kembhavi, Aniruddha}, booktitle = {CVPR}, doi = {10.1109/CVPR52734.2025.00018}, month = jun, title = {Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models}, url = {http://openaccess.thecvf.com/content/CVPR2025/html/Deitke_Molmo_and_PixMo_Open_Weights_and_Open_Data_for_State-of-the-Art_CVPR_2025_paper.html}, year = {2025} } -
 DrawEduMath: Evaluating Vision Language Models with Expert-Annotated Students’ Hand-Drawn Math ImagesSami Baral, Li Lucy, Ryan Knight, Alice Ng, Luca Soldaini, Neil T Heffernan, and Kyle LoIn NAACL, Apr 2025
DrawEduMath: Evaluating Vision Language Models with Expert-Annotated Students’ Hand-Drawn Math ImagesSami Baral, Li Lucy, Ryan Knight, Alice Ng, Luca Soldaini, Neil T Heffernan, and Kyle LoIn NAACL, Apr 2025Outstanding Paper Award
In real-world settings, vision language models (VLMs) should robustly handle naturalistic, noisy visual content as well as domain-specific language and concepts. For example, K-12 educators using digital learning platforms may need to examine and provide feedback across many images of students’ math work. To assess the potential of VLMs to support educators in settings like this one, we introduce DrawEduMath, an English-language dataset of 2,030 images of students’ handwritten responses to K-12 math problems. Teachers provided detailed annotations, including free-form descriptions of each image and 11,661 question-answer (QA) pairs. These annotations capture a wealth of pedagogical insights, ranging from students’ problem-solving strategies to the composition of their drawings, diagrams, and writing. We evaluate VLMs on teachers’ QA pairs, as well as 44,362 synthetic QA pairs derived from teachers’ descriptions using language models (LMs). We show that even state-of-the-art VLMs leave much room for improvement on DrawEduMath questions. We also find that synthetic QAs, though imperfect, can yield similar model rankings as teacher-written QAs. We release DrawEduMath to support the evaluation of VLMs’ abilities to reason mathematically over images gathered with educational contexts in mind.
@inproceedings{Baral2025DrawedumathEvaluatingVision, author = {Baral, Sami and Lucy, Li and Knight, Ryan and Ng, Alice and Soldaini, Luca and Heffernan, Neil T and Lo, Kyle}, booktitle = {NAACL}, doi = {10.18653/v1/2025.naacl-long.352}, month = apr, title = {DrawEduMath: Evaluating Vision Language Models with Expert-Annotated Students' Hand-Drawn Math Images}, url = {https://aclanthology.org/2025.naacl-long.352/}, year = {2025} } -
 RouterRetriever: Routing over a Mixture of Expert Embedding ModelsHyunji Lee, Luca Soldaini, Arman Cohan, Minjoon Seo, and Kyle LoIn AAAI, Apr 2025
RouterRetriever: Routing over a Mixture of Expert Embedding ModelsHyunji Lee, Luca Soldaini, Arman Cohan, Minjoon Seo, and Kyle LoIn AAAI, Apr 2025Information retrieval methods often rely on a single embedding model trained on large, general-domain datasets like MSMARCO. While this approach can produce a retriever with reasonable overall performance, they often underperform models trained on domain-specific data when testing on their respective domains. Prior work in information retrieval has tackled this through multi-task training, but the idea of routing over a mixture of domain-specific expert retrievers remains unexplored despite the popularity of such ideas in language model generation research. In this work, we introduce RouterRetriever, a retrieval model that leverages a mixture of domain-specific experts by using a routing mechanism to select the most appropriate expert for each query. RouterRetriever is lightweight and allows easy addition or removal of experts without additional training. Evaluation on the BEIR benchmark demonstrates that RouterRetriever outperforms both models trained on MSMARCO (+2.1 absolute nDCG@10) and multi-task models (+3.2). This is achieved by employing our routing mechanism, which surpasses other routing techniques (+1.8 on average) commonly used in language modeling. Furthermore, the benefit generalizes well to other datasets, even in the absence of a specific expert on the dataset. RouterRetriever is the first work to demonstrate the advantages of routing over a mixture of domain-specific expert embedding models as an alternative to a single, general-purpose embedding model, especially when retrieving from diverse, specialized domains.
@inproceedings{Lee2024RouterRetrieverET, author = {Lee, Hyunji and Soldaini, Luca and Cohan, Arman and Seo, Minjoon and Lo, Kyle}, booktitle = {AAAI}, doi = {10.1609/aaai.v39i11.33306}, month = apr, title = {RouterRetriever: Routing over a Mixture of Expert Embedding Models}, url = {https://arxiv.org/abs/2409.02685}, volume = {2409.02685}, year = {2025} } -
 Olmoe: Open mixture-of-experts language modelsNiklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, and 17 more authorsIn ICLR, Apr 2025
Olmoe: Open mixture-of-experts language modelsNiklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, and 17 more authorsIn ICLR, Apr 2025We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present novel findings on MoE training, define and analyze new routing properties showing high specialization in our model, and open-source all our work: model weights, training data, code, and logs.
@inproceedings{Muennighoff2024OLMoEOM, author = {Muennighoff, Niklas and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Morrison, Jacob and Min, Sewon and Shi, Weijia and Walsh, Pete and Tafjord, Oyvind and Lambert, Nathan and Gu, Yuling and Arora, Shane and Bhagia, Akshita and Schwenk, Dustin and Wadden, David and Wettig, Alexander and Hui, Binyuan and Dettmers, Tim and Kiela, Douwe and Farhadi, Ali and Smith, Noah A and Koh, Pang Wei and Singh, Amanpreet and Hajishirzi, Hannaneh}, booktitle = {ICLR}, month = apr, title = {Olmoe: Open mixture-of-experts language models}, url = {https://openreview.net/forum?id=xXTkbTBmqq}, year = {2025} } -
 olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language ModelsJake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wilhelm, and 2 more authorsArXiv, Feb 2025
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language ModelsJake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wilhelm, and 2 more authorsArXiv, Feb 2025PDF documents have the potential to provide trillions of novel, high-quality tokens for training language models. However, these documents come in a diversity of types with differing formats and visual layouts that pose a challenge when attempting to extract and faithfully represent the underlying content for language model use. Traditional open source tools often produce lower quality extractions compared to vision language models (VLMs), but reliance on the best VLMs can be prohibitively costly (e.g., over 6,240 USD per million PDF pages for GPT-4o) or infeasible if the PDFs cannot be sent to proprietary APIs. We present olmOCR, an open-source toolkit for processing PDFs into clean, linearized plain text in natural reading order while preserving structured content like sections, tables, lists, equations, and more. Our toolkit runs a fine-tuned 7B vision language model (VLM) trained on olmOCR-mix-0225, a sample of 260,000 pages from over 100,000 crawled PDFs with diverse properties, including graphics, handwritten text and poor quality scans. olmOCR is optimized for large-scale batch processing, able to scale flexibly to different hardware setups and can convert a million PDF pages for only 176 USD. To aid comparison with existing systems, we also introduce olmOCR-Bench, a curated set of 1,400 PDFs capturing many content types that remain challenging even for the best tools and VLMs, including formulas, tables, tiny fonts, old scans, and more. We find olmOCR outperforms even top VLMs including GPT-4o, Gemini Flash 2 and Qwen-2.5-VL. We openly release all components of olmOCR: our fine-tuned VLM model, training code and data, an efficient inference pipeline that supports vLLM and SGLang backends, and benchmark olmOCR-Bench.
@article{Poznanski2025OlmocrUnlockingTrillions, author = {Poznanski, Jake and Rangapur, Aman and Borchardt, Jon and Dunkelberger, Jason and Huff, Regan and Lin, Daniel and Wilhelm, Christopher and Lo, Kyle and Soldaini, Luca}, journal = {ArXiv}, month = feb, title = {olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models}, url = {https://arxiv.org/abs/2502.18443}, volume = {2502.18443}, year = {2025} } -
 Automatic detection of research values from scientific abstracts across computer science subfieldsHang Jiang, Tal August, Luca Soldaini, Kyle Lo, and Maria AntoniakArXiv, Feb 2025
Automatic detection of research values from scientific abstracts across computer science subfieldsHang Jiang, Tal August, Luca Soldaini, Kyle Lo, and Maria AntoniakArXiv, Feb 2025The field of Computer science (CS) has rapidly evolved over the past few decades, providing computational tools and methodologies to various fields and forming new interdisciplinary communities. This growth in CS has significantly impacted institutional practices and relevant research communities. Therefore, it is crucial to explore what specific research values, known as basic and fundamental beliefs that guide or motivate research attitudes or actions, CS-related research communities promote. Prior research has manually analyzed research values from a small sample of machine learning papers. No prior work has studied the automatic detection of research values in CS from large-scale scientific texts across different research subfields. This paper introduces a detailed annotation scheme featuring ten research values that guide CS-related research. Based on the scheme, we build value classifiers to scale up the analysis and present a systematic study over 226,600 paper abstracts from 32 CS-related subfields and 86 popular publishing venues over ten years.
@article{Jiang2025AutomaticDetectionOf, author = {Jiang, Hang and August, Tal and Soldaini, Luca and Lo, Kyle and Antoniak, Maria}, journal = {ArXiv}, month = feb, title = {Automatic detection of research values from scientific abstracts across computer science subfields}, url = {https://arxiv.org/abs/2502.16390}, volume = {2502.16390}, year = {2025} }
















2024
-
 ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language ModelsBenjamin Newman, Yoonjoo Lee, Aakanksha Naik, Pao Siangliulue, Raymond Fok, Juho Kim, Daniel S Weld, and 2 more authorsIn EMNLP, Nov 2024
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language ModelsBenjamin Newman, Yoonjoo Lee, Aakanksha Naik, Pao Siangliulue, Raymond Fok, Juho Kim, Daniel S Weld, and 2 more authorsIn EMNLP, Nov 2024When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs’ abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
@inproceedings{Newman2024ArxivdigestablesSynthesizingScientific, author = {Newman, Benjamin and Lee, Yoonjoo and Naik, Aakanksha and Siangliulue, Pao and Fok, Raymond and Kim, Juho and Weld, Daniel S and Chang, Joseph Chee and Lo, Kyle}, booktitle = {EMNLP}, doi = {10.18653/v1/2024.emnlp-main.538}, month = nov, title = {ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models}, url = {https://aclanthology.org/2024.emnlp-main.538}, year = {2024} } -
 2 OLMo 2 FuriousTeam OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, and 33 more authorsIn COLM, Oct 2024
2 OLMo 2 FuriousTeam OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, and 33 more authorsIn COLM, Oct 2024We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from Tülu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly – models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
@inproceedings{OLMo2024Olmo, author = {OLMo, Team and Walsh, Pete and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Arora, Shane and Bhagia, Akshita and Gu, Yuling and Huang, Shengyi and Jordan, Matt and Lambert, Nathan and Schwenk, Dustin and Tafjord, Oyvind and Anderson, Taira and Atkinson, David and Brahman, Faeze and Clark, Christopher and Dasigi, Pradeep and Dziri, Nouha and Guerquin, Michal and Ivison, Hamish and Koh, Pang Wei and Liu, Jiacheng and Malik, Saumya and Merrill, William and Miranda, Lester James V and Morrison, Jacob and Murray, Tyler and Nam, Crystal and Pyatkin, Valentina and Rangapur, Aman and Schmitz, Michael and Skjonsberg, Sam and Wadden, David and Wilhelm, Christopher and Wilson, Michael and Zettlemoyer, Luke and Farhadi, Ali and Smith, Noah A and Hajishirzi, Hannaneh}, booktitle = {COLM}, month = oct, cv_authors_after = {Team OLMo}, cv_authors_before = {Team OLMo}, title = {2 OLMo 2 Furious}, url = {https://arxiv.org/abs/2501.00656}, year = {2024} } -
 The Semantic Reader Project: Augmenting Scholarly Documents Through AI-Powered Interactive Reading InterfacesKyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X. Zhang, Cassidy Trier, Chloe Anastasiades, and 48 more authorsCommunications of the ACM, Sep 2024
The Semantic Reader Project: Augmenting Scholarly Documents Through AI-Powered Interactive Reading InterfacesKyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X. Zhang, Cassidy Trier, Chloe Anastasiades, and 48 more authorsCommunications of the ACM, Sep 2024Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the greater the need for new technology to support scholars. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. For instance, the PDF format for sharing papers remains widely used due to its portability but has significant downsides, inter alia, static content and poor accessibility for low-vision readers. This paper explores the question “Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces—even for legacy PDFs?” We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we’ve developed a collection of novel reading interfaces and evaluated them with study participants and real-world users to show improved reading experiences for scholars. We’ve also released a production research paper reading interface that will continuously incorporate novel features from our research as they mature. We structure this paper around five key opportunities for AI assistance in scholarly reading —discovery, efficiency, comprehension, synthesis, and accessibility—and present an overview of our progress and discuss remaining open challenges.Augmenting scholarly documents through AI-powered interactive reading interfaces.
@article{Lo2024SemanticReaderProject, author = {Lo, Kyle and Chang, Joseph Chee and Head, Andrew and Bragg, Jonathan and Zhang, Amy X. and Trier, Cassidy and Anastasiades, Chloe and August, Tal and Authur, Russell and Bragg, Danielle and Bransom, Erin and Cachola, Isabel and Candra, Stefan and Chandrasekhar, Yoganand and Chen, Yen-Sung and Cheng, Evie Yu-Yen and Chou, Yvonne and Downey, Doug and Evans, Rob and Fok, Raymond and Hu, Fangzhou and Huff, Regan and Kang, Dongyeop and Kim, Tae Soo and Kinney, Rodney and Kittur, Aniket and Kang, Hyeonsu B. and Klevak, Egor and Kuehl, Bailey and Langan, Michael J. and Latzke, Matt and Lochner, Jaron and MacMillan, Kelsey and Marsh, Eric and Murray, Tyler and Naik, Aakanksha and Nguyen, Ngoc-Uyen and Palani, Srishti and Park, Soya and Paulic, Caroline and Rachatasumrit, Napol and Rao, Smita and Sayre, Paul and Shen, Zejiang and Siangliulue, Pao and Soldaini, Luca and Tran, Huy and van Zuylen, Madeleine and Wang, Lucy Lu and Wilhelm, Christopher and Wu, Caroline and Yang, Jiangjiang and Zamarron, Angele and Hearst, Marti A. and Weld, Daniel S.}, doi = {10.1145/3659096}, journal = {Communications of the ACM}, month = sep, cv_authors_after = {Cassidy Trier}, cv_authors_before = {Marti Hearst}, title = {The Semantic Reader Project: Augmenting Scholarly Documents Through AI-Powered Interactive Reading Interfaces}, url = {https://doi.org/10.1145/3659096}, volume = {67}, year = {2024} } -
 OLMo: Accelerating the Science of Language ModelsDirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, and 36 more authorsIn ACL, Aug 2024
OLMo: Accelerating the Science of Language ModelsDirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, and 36 more authorsIn ACL, Aug 2024Best Paper Award
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
@inproceedings{Groeneveld2024OlmoAcceleratingScience, author = {Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, William and Strubell, Emma and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Zettlemoyer, Luke and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah and Hajishirzi, Hannaneh}, booktitle = {ACL}, doi = {10.18653/v1/2024.acl-long.841}, month = aug, cv_authors_after = {Oyvind Tafjord}, cv_authors_before = {Pradeep Dasigi}, title = {{OLM}o: Accelerating the Science of Language Models}, url = {https://aclanthology.org/2024.acl-long.841}, year = {2024} } -
 MathFish : Evaluating Language Model Math Reasoning via Grounding in Educational CurriculaLi Lucy, Tal August, Rose E. Wang, Luca Soldaini, Courtney Allison, and Kyle LoArXiv, Aug 2024
MathFish : Evaluating Language Model Math Reasoning via Grounding in Educational CurriculaLi Lucy, Tal August, Rose E. Wang, Luca Soldaini, Courtney Allison, and Kyle LoArXiv, Aug 2024To ensure that math curriculum is grade-appropriate and aligns with critical skills or concepts in accordance with educational standards, pedagogical experts can spend months carefully reviewing published math problems. Drawing inspiration from this process, our work presents a novel angle for evaluating language models’ (LMs) mathematical abilities, by investigating whether they can discern skills and concepts enabled by math content. We contribute two datasets: one consisting of 385 fine-grained descriptions of K-12 math skills and concepts, or standards, from Achieve the Core (ATC), and another of 9.9K math problems labeled with these standards (MathFish). We develop two tasks for evaluating LMs’ abilities to assess math problems: (1) verifying whether a problem aligns with a given standard, and (2) tagging a problem with all aligned standards. Working with experienced teachers, we find that LMs struggle to tag and verify standards linked to problems, and instead predict labels that are close to ground truth, but differ in subtle ways. We also show that LMs often generate problems that do not fully align with standards described in prompts, suggesting the need for careful scrutiny on use cases involving LMs for generating curricular materials. Finally, we categorize problems in GSM8k using math standards, allowing us to better understand why some problems are more difficult to solve for models than others.
@article{Lucy2024EvaluatingLM, author = {Lucy, Li and August, Tal and Wang, Rose E. and Soldaini, Luca and Allison, Courtney and Lo, Kyle}, journal = {ArXiv}, month = aug, title = {MathFish : Evaluating Language Model Math Reasoning via Grounding in Educational Curricula}, url = {https://arxiv.org/abs/2408.04226}, year = {2024} } -
 Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining ResearchLuca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, and 29 more authorsIn ACL, Aug 2024
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining ResearchLuca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, and 29 more authorsIn ACL, Aug 2024Best Paper Award
Information about pretraining corpora used to train the current best-performing language models is seldom discussed: commercial models rarely detail their data, and even open models are often released without accompanying training data or recipes to reproduce them. As a result, it is challenging to conduct and advance scientific research on language modeling, such as understanding how training data impacts model capabilities and limitations. To facilitate scientific research on language model pretraining, we curate and release Dolma, a three-trillion-token English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. We extensively document Dolma, including its design principles, details about its construction, and a summary of its contents. We present analyses and experimental results on intermediate states of Dolma to share what we have learned about important data curation practices. Finally, we open-source our data curation toolkit to enable reproduction of our work as well as support further research in large-scale data curation.
@inproceedings{Soldaini2024DolmaOpenCorpus, author = {Soldaini, Luca and Kinney, Rodney and Bhagia, Akshita and Schwenk, Dustin and Atkinson, David and Authur, Russell and Bogin, Ben and Chandu, Khyathi and Dumas, Jennifer and Elazar, Yanai and Hofmann, Valentin and Jha, Ananya and Kumar, Sachin and Lucy, Li and Lyu, Xinxi and Lambert, Nathan and Magnusson, Ian and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew and Ravichander, Abhilasha and Richardson, Kyle and Shen, Zejiang and Strubell, Emma and Subramani, Nishant and Tafjord, Oyvind and Walsh, Evan and Zettlemoyer, Luke and Smith, Noah and Hajishirzi, Hannaneh and Beltagy, Iz and Groeneveld, Dirk and Dodge, Jesse and Lo, Kyle}, booktitle = {ACL}, doi = {10.18653/v1/2024.acl-long.840}, month = aug, cv_authors_after = {Dustin Schwenk}, cv_authors_before = {Noah Smith}, title = {Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research}, url = {https://aclanthology.org/2024.acl-long.840}, year = {2024} } -
 KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research QuestionsFangyuan Xu, Kyle Lo, Luca Soldaini, Bailey Kuehl, Eunsol Choi, and David WaddenIn Findings of the Association for Computational Linguistics ACL 2024, Aug 2024
KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research QuestionsFangyuan Xu, Kyle Lo, Luca Soldaini, Bailey Kuehl, Eunsol Choi, and David WaddenIn Findings of the Association for Computational Linguistics ACL 2024, Aug 2024Large language models (LLMs) adapted to follow user instructions are now widely deployed as conversational agents. In this work, we examine one increasingly common instruction-following task: providing writing assistance to compose a long-form answer. To evaluate the capabilities of current LLMs on this task, we construct KIWI, a dataset of knowledge-intensive writing instructions in the scientific domain. Given a research question, an initial model-generated answer and a set of relevant papers, an expert annotator iteratively issues instructions for the model to revise and improve its answer. We collect 1,260 interaction turns from 234 interaction sessions with three state-of-the-art LLMs. Each turn includes a user instruction, a model response, and a human evaluation of the model response. Through a detailed analysis of the collected responses, we find that all models struggle to incorporate new information into an existing answer, and to perform precise and unambiguous edits. Further, we find that models struggle to judge whether their outputs successfully followed user instructions, with accuracy at least 10 points short of human agreement. Our findings indicate that KIWI will be a valuable resource to measure progress and improve LLMs’ instruction-following capabilities for knowledge intensive writing tasks.
@inproceedings{Xu2024KiwiDatasetKnowledge, author = {Xu, Fangyuan and Lo, Kyle and Soldaini, Luca and Kuehl, Bailey and Choi, Eunsol and Wadden, David}, booktitle = {Findings of the Association for Computational Linguistics ACL 2024}, doi = {10.18653/v1/2024.findings-acl.770}, month = aug, title = {{KIWI}: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions}, url = {https://aclanthology.org/2024.findings-acl.770}, year = {2024} } -
 DataComp-LM: In search of the next generation of training sets for language modelsJeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, and 52 more authorsIn NeurIPS (Datasets and Benchmarks), Dec 2024
DataComp-LM: In search of the next generation of training sets for language modelsJeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, and 52 more authorsIn NeurIPS (Datasets and Benchmarks), Dec 2024We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
@inproceedings{Gadre2023DataCompIS, author = {Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yonatan and Nezhurina, Marianna and Abbas, Amro and Hsieh, Cheng-Yu and Ghosh, Dhruba and Gardner, Josh and Kilian, Maciej and Zhang, Hanlin and Shao, Rulin and Pratt, Sarah and Sanyal, Sunny and Ilharco, Gabriel and Daras, Giannis and Marathe, Kalyani and Gokaslan, Aaron and Zhang, Jieyu and Chandu, Khyathi and Nguyen, Thao and Vasiljevic, Igor and Kakade, Sham and Song, Shuran and Sanghavi, Sujay and Faghri, Fartash and Oh, Sewoong and Zettlemoyer, Luke and Lo, Kyle and El-Nouby, Alaaeldin and Pouransari, Hadi and Toshev, Alexander and Wang, Stephanie and Groeneveld, Dirk and Soldaini, Luca and Koh, Pang Wei and Jitsev, Jenia and Kollar, Thomas and Dimakis, Alexandros G. and Carmon, Yair and Dave, Achal and Schmidt, Ludwig and Shankar, Vaishaal}, booktitle = {NeurIPS (Datasets and Benchmarks)}, month = dec, title = {DataComp-LM: In search of the next generation of training sets for language models}, url = {https://proceedings.neurips.cc/paper_files/paper/2024/hash/19e4ea30dded58259665db375885e412-Abstract-Datasets_and_Benchmarks_Track.html}, year = {2024} } -
 One Thousand and One Pairs: A "novel" challenge for long-context language modelsMarzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit IyyerIn EMNLP, Nov 2024
One Thousand and One Pairs: A "novel" challenge for long-context language modelsMarzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit IyyerIn EMNLP, Nov 2024Synthetic long-context LLM benchmarks (e.g., "needle-in-the-haystack") test only surface-level retrieval capabilities, but how well can long-context LLMs retrieve, synthesize, and reason over information across book-length inputs? We address this question by creating NoCha, a dataset of 1,001 minimally different pairs of true and false claims about 67 recently-published English fictional books, written by human readers of those books. In contrast to existing long-context benchmarks, our annotators confirm that the largest share of pairs in NoCha require global reasoning over the entire book to verify. Our experiments show that while human readers easily perform this task, it is enormously challenging for all ten long-context LLMs that we evaluate: no open-weight model performs above random chance (despite their strong performance on synthetic benchmarks), while GPT-4o achieves the highest accuracy at 55.8%. Further analysis reveals that (1) on average, models perform much better on pairs that require only sentence-level retrieval vs. global reasoning; (2) model-generated explanations for their decisions are often inaccurate even for correctly-labeled claims; and (3) models perform substantially worse on speculative fiction books that contain extensive world-building. The methodology proposed in NoCha allows for the evolution of the benchmark dataset and the easy analysis of future models.
@inproceedings{Karpinska2024OneTA, author = {Karpinska, Marzena and Thai, Katherine and Lo, Kyle and Goyal, Tanya and Iyyer, Mohit}, booktitle = {EMNLP}, doi = {10.18653/v1/2024.emnlp-main.948}, month = nov, title = {One Thousand and One Pairs: A "novel" challenge for long-context language models}, url = {https://aclanthology.org/2024.emnlp-main.948}, year = {2024} } -
 SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific LiteratureDavid Wadden, Kejian Shi, Jacob Daniel Morrison, Aakanksha Naik, Shruti Singh, Nitzan Barzilay, Kyle Lo, and 6 more authorsArXiv, Jun 2024
SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific LiteratureDavid Wadden, Kejian Shi, Jacob Daniel Morrison, Aakanksha Naik, Shruti Singh, Nitzan Barzilay, Kyle Lo, and 6 more authorsArXiv, Jun 2024We present SciRIFF (Scientific Resource for Instruction-Following and Finetuning), a dataset of 137K instruction-following demonstrations for 54 tasks covering five essential scientific literature understanding capabilities: information extraction, summarization, question answering, claim verification, and classification. SciRIFF demonstrations are notable for their long input contexts, detailed task specifications, and complex structured outputs. While instruction-following resources are available in specific domains such as clinical medicine and chemistry, SciRIFF is the first dataset focused on extracting and synthesizing information from research literature across a wide range of scientific fields. To demonstrate the utility of SciRIFF, we develop a sample-efficient strategy to adapt a general instruction-following model for science by performing additional finetuning on a mix of general-domain and SciRIFF demonstrations. In evaluations on nine held-out scientific tasks, our model – called SciTulu – improves over a strong LLM baseline by 28.1% and 6.5% at the 7B and 70B scales respectively, while maintaining general instruction-following performance within 2% of the baseline. We are optimistic that SciRIFF will facilitate the development and evaluation of LLMs to help researchers navigate the ever-growing body of scientific literature. We release our dataset, model checkpoints, and data processing and evaluation code to enable further research.
@article{Wadden2024SciRIFFAR, author = {Wadden, David and Shi, Kejian and Morrison, Jacob Daniel and Naik, Aakanksha and Singh, Shruti and Barzilay, Nitzan and Lo, Kyle and Hope, Tom and Soldaini, Luca and Shen, Shannon Zejiang and Downey, Doug and Hajishirzi, Hanna and Cohan, Arman}, journal = {ArXiv}, month = jun, title = {SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific Literature}, url = {https://arxiv.org/abs/2406.07835}, year = {2024} } -
 The responsible foundation model development cheatsheet: A review of tools & resourcesShayne Longpre, Stella Biderman, Alon Albalak, Hailey Schoelkopf, Daniel McDuff, Sayash Kapoor, Kevin Klyman, and 16 more authorsArXiv, Jun 2024
The responsible foundation model development cheatsheet: A review of tools & resourcesShayne Longpre, Stella Biderman, Alon Albalak, Hailey Schoelkopf, Daniel McDuff, Sayash Kapoor, Kevin Klyman, and 16 more authorsArXiv, Jun 2024Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
@article{Longpre2024ResponsibleFoundation, author = {Longpre, Shayne and Biderman, Stella and Albalak, Alon and Schoelkopf, Hailey and McDuff, Daniel and Kapoor, Sayash and Klyman, Kevin and Lo, Kyle and Ilharco, Gabriel and San, Nay and Rauh, Maribeth and Skowron, Aviya and Vidgen, Bertie and Weidinger, Laura and Narayanan, Arvind and Sanh, Victor and Adelani, David and Liang, Percy and Bommasani, Rishi and Henderson, Peter and Luccioni, Sasha and Jernite, Yacine and Soldaini, Luca}, journal = {ArXiv}, month = jun, title = {The responsible foundation model development cheatsheet: A review of tools & resources}, url = {https://arxiv.org/abs/2406.16746}, volume = {2406.16746}, year = {2024} } -
 Know Your Audience: The benefits and pitfalls of generating plain language summaries beyond the "general" audienceTal August, Kyle Lo, Noah A. Smith, and Katharina ReineckeIn CHI, May 2024
Know Your Audience: The benefits and pitfalls of generating plain language summaries beyond the "general" audienceTal August, Kyle Lo, Noah A. Smith, and Katharina ReineckeIn CHI, May 2024Language models (LMs) show promise as tools for communicating science to the general public by simplifying and summarizing complex language. Because models can be prompted to generate text for a specific audience (e.g., college-educated adults), LMs might be used to create multiple versions of plain language summaries for people with different familiarities of scientific topics. However, it is not clear what the benefits and pitfalls of adaptive plain language are. When is simplifying necessary, what are the costs in doing so, and do these costs differ for readers with different background knowledge? Through three within-subjects studies in which we surface summaries for different envisioned audiences to participants of different backgrounds, we found that while simpler text led to the best reading experience for readers with little to no familiarity in a topic, high familiarity readers tended to ignore certain details in overly plain summaries (e.g., study limitations). Our work provides methods and guidance on ways of adapting plain language summaries beyond the single “general” audience.
@inproceedings{August2024KnowYourAudience, author = {August, Tal and Lo, Kyle and Smith, Noah A. and Reinecke, Katharina}, booktitle = {CHI}, doi = {10.1145/3613904.3642289}, month = may, title = {Know Your Audience: The benefits and pitfalls of generating plain language summaries beyond the "general" audience}, url = {https://doi.org/10.1145/3613904.3642289}, year = {2024} } -
 Booookscore: A systematic exploration of book-length summarization in the era of llmsYapei Chang, Kyle Lo, Tanya Goyal, and Mohit IyyerIn ICLR, May 2024
Booookscore: A systematic exploration of book-length summarization in the era of llmsYapei Chang, Kyle Lo, Tanya Goyal, and Mohit IyyerIn ICLR, May 2024Summarizing book-length documents (100K tokens) that exceed the context window size of large language models (LLMs) requires first breaking the input document into smaller chunks and then prompting an LLM to merge, update, and compress chunk-level summaries. Despite the complexity and importance of this task, it has yet to be meaningfully studied due to the challenges of evaluation: existing book-length summarization datasets (e.g., BookSum) are in the pretraining data of most public LLMs, and existing evaluation methods struggle to capture errors made by modern LLM summarizers. In this paper, we present the first study of the coherence of LLM-based book-length summarizers implemented via two prompting workflows: (1) hierarchically merging chunk-level summaries, and (2) incrementally updating a running summary. We obtain 1193 fine-grained human annotations on GPT-4 generated summaries of 100 recently-published books and identify eight common types of coherence errors made by LLMs. Because human evaluation is expensive and time-consuming, we develop an automatic metric, BooookScore, that measures the proportion of sentences in a summary that do not contain any of the identified error types. BooookScore has high agreement with human annotations and allows us to systematically evaluate the impact of many other critical parameters (e.g., chunk size, base LLM) while saving $15K USD and 500 hours in human evaluation costs. We find that closed-source LLMs such as GPT-4 and Claude 2 produce summaries with higher BooookScore than those generated by open-source models. While LLaMA 2 falls behind other models, Mixtral achieves performance on par with GPT-3.5-Turbo. Incremental updating yields lower BooookScore but higher level of detail than hierarchical merging, a trade-off sometimes preferred by annotators. We release code and annotations to spur more principled research on book-length summarization.
@inproceedings{Chang2023BooookScoreAS, author = {Chang, Yapei and Lo, Kyle and Goyal, Tanya and Iyyer, Mohit}, booktitle = {ICLR}, month = may, title = {Booookscore: A systematic exploration of book-length summarization in the era of llms}, url = {https://openreview.net/forum?id=7Ttk3RzDeu}, year = {2024} } -
 FollowIR: Evaluating and Teaching Information Retrieval Models to Follow InstructionsOrion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and 1 more authorArXiv, May 2024
FollowIR: Evaluating and Teaching Information Retrieval Models to Follow InstructionsOrion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and 1 more authorArXiv, May 2024Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions – also known as narratives – developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
@article{Weller2024FollowIREA, author = {Weller, Orion and Chang, Benjamin and MacAvaney, Sean and Lo, Kyle and Cohan, Arman and Durme, Benjamin Van and Lawrie, Dawn and Soldaini, Luca}, journal = {ArXiv}, month = may, title = {FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions}, url = {https://arxiv.org/abs/2403.15246}, year = {2024} } -
 FABLES: Evaluating faithfulness and content selection in book-length summarizationYekyung Kim, Yapei Chang, Marzena Karpinska, Aparna Garimella, Varun Manjunatha, Kyle Lo, Tanya Goyal, and 1 more authorArXiv, Apr 2024
FABLES: Evaluating faithfulness and content selection in book-length summarizationYekyung Kim, Yapei Chang, Marzena Karpinska, Aparna Garimella, Varun Manjunatha, Kyle Lo, Tanya Goyal, and 1 more authorArXiv, Apr 2024While long-context large language models (LLMs) can technically summarize book-length documents (>100K tokens), the length and complexity of the documents have so far prohibited evaluations of input-dependent aspects like faithfulness. In this paper, we conduct the first large-scale human evaluation of faithfulness and content selection on LLM-generated summaries of fictional books. Our study mitigates the issue of data contamination by focusing on summaries of books published in 2023 or 2024, and we hire annotators who have fully read each book prior to the annotation task to minimize cost and cognitive burden. We collect FABLES, a dataset of annotations on 3,158 claims made in LLM-generated summaries of 26 books, at a cost of $5.2K USD, which allows us to rank LLM summarizers based on faithfulness: Claude-3-Opus significantly outperforms all closed-source LLMs, while the open-source Mixtral is on par with GPT-3.5-Turbo. An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate. While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims. Our experiments suggest that detecting unfaithful claims is an important future direction not only for summarization evaluation but also as a testbed for long-context understanding. Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
@article{Kim2024FABLESEF, author = {Kim, Yekyung and Chang, Yapei and Karpinska, Marzena and Garimella, Aparna and Manjunatha, Varun and Lo, Kyle and Goyal, Tanya and Iyyer, Mohit}, journal = {ArXiv}, month = apr, title = {FABLES: Evaluating faithfulness and content selection in book-length summarization}, url = {https://arxiv.org/abs/2404.01261}, year = {2024} } -
 Accelerating Scientific Paper Skimming with Augmented Intelligence Through Customizable Faceted HighlightsRaymond Fok, Luca Soldaini, Cassidy Trier, Erin Bransom, Kelsey MacMillan, Evie Cheng, Hita Kambhamettu, and 5 more authorsACM Transactions on Interactive Intelligent Systems, Mar 2024
Accelerating Scientific Paper Skimming with Augmented Intelligence Through Customizable Faceted HighlightsRaymond Fok, Luca Soldaini, Cassidy Trier, Erin Bransom, Kelsey MacMillan, Evie Cheng, Hita Kambhamettu, and 5 more authorsACM Transactions on Interactive Intelligent Systems, Mar 2024Scholars need to keep up with an exponentially increasing flood of scientific papers. To aid this challenge, we introduce Scim, a novel intelligent interface that helps scholars skim papers to rapidly review and gain a cursory understanding of its contents. Scim supports the skimming process by highlighting salient content within a paper, directing a scholar’s attention. These automatically-extracted highlights are faceted by content type, evenly distributed across a paper, and have a density configurable by scholars. We evaluate Scim with an in-lab usability study and a longitudinal diary study, revealing how its highlights facilitate the more efficient construction of a conceptualization of a paper. Finally, we describe the process of scaling highlights from their conception within Scim, a research prototype, to production on over 521,000 papers within the Semantic Reader, a publicly-available augmented reading interface for scientific papers. We conclude by discussing design considerations and tensions for the design of future skimming tools with augmented intelligence.
@article{Fok2024AcceleratingScientificPaper, author = {Fok, Raymond and Soldaini, Luca and Trier, Cassidy and Bransom, Erin and MacMillan, Kelsey and Cheng, Evie and Kambhamettu, Hita and Bragg, Jonathan and Lo, Kyle and Hearst, Marti A. and Head, Andrew and Weld, Daniel S.}, doi = {10.1145/3665648}, journal = {ACM Transactions on Interactive Intelligent Systems}, month = mar, title = {Accelerating Scientific Paper Skimming with Augmented Intelligence Through Customizable Faceted Highlights}, url = {https://doi.org/10.1145/3665648}, volume = {14}, year = {2024} } -
 InfoLossQA: Characterizing and Recovering Information Loss in Text SummarizationJan Trienes, Sebastian Antony Joseph, Jorg Schlotterer, Christin Seifert, Kyle Lo, Wei Xu, Byron C. Wallace, and 1 more authorArXiv, Jan 2024
InfoLossQA: Characterizing and Recovering Information Loss in Text SummarizationJan Trienes, Sebastian Antony Joseph, Jorg Schlotterer, Christin Seifert, Kyle Lo, Wei Xu, Byron C. Wallace, and 1 more authorArXiv, Jan 2024Text simplification aims to make technical texts more accessible to laypeople but often results in deletion of information and vagueness. This work proposes InfoLossQA, a framework to characterize and recover simplification-induced information loss in form of question-and-answer (QA) pairs. Building on the theory of Question Under Discussion, the QA pairs are designed to help readers deepen their knowledge of a text. We conduct a range of experiments with this framework. First, we collect a dataset of 1,000 linguist-curated QA pairs derived from 104 LLM simplifications of scientific abstracts of medical studies. Our analyses of this data reveal that information loss occurs frequently, and that the QA pairs give a high-level overview of what information was lost. Second, we devise two methods for this task: end-to-end prompting of open-source and commercial language models, and a natural language inference pipeline. With a novel evaluation framework considering the correctness of QA pairs and their linguistic suitability, our expert evaluation reveals that models struggle to reliably identify information loss and applying similar standards as humans at what constitutes information loss.
@article{Trienes2024InfoLossQACA, author = {Trienes, Jan and Joseph, Sebastian Antony and Schlotterer, Jorg and Seifert, Christin and Lo, Kyle and Xu, Wei and Wallace, Byron C. and Li, Junyi Jessy}, journal = {ArXiv}, month = jan, title = {InfoLossQA: Characterizing and Recovering Information Loss in Text Summarization}, url = {https://arxiv.org/abs/2401.16475}, year = {2024} } -
 Paloma: A Benchmark for Evaluating Language Model FitIan Magnusson, Akshita Bhagia, Valentin Hofmann, Luca Soldaini, A. Jha, Oyvind Tafjord, Dustin Schwenk, and 9 more authorsIn NeurIPS (Datasets and Benchmarks), Dec 2024
Paloma: A Benchmark for Evaluating Language Model FitIan Magnusson, Akshita Bhagia, Valentin Hofmann, Luca Soldaini, A. Jha, Oyvind Tafjord, Dustin Schwenk, and 9 more authorsIn NeurIPS (Datasets and Benchmarks), Dec 2024Language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains—varying distributions of language. Rather than assuming perplexity on one distribution extrapolates to others, Perplexity Analysis for Language Model Assessment (Paloma), measures LM fit to 585 text domains, ranging from nytimes.com to r/depression on Reddit. We invite submissions to our benchmark and organize results by comparability based on compliance with guidelines such as removal of benchmark contamination from pretraining. Submissions can also record parameter and training token count to make comparisons of Pareto efficiency for performance as a function of these measures of cost. We populate our benchmark with results from 6 baselines pretrained on popular corpora. In case studies, we demonstrate analyses that are possible with Paloma, such as finding that pretraining without data beyond Common Crawl leads to inconsistent fit to many domains.
@inproceedings{Magnusson2023PalomaAB, author = {Magnusson, Ian and Bhagia, Akshita and Hofmann, Valentin and Soldaini, Luca and Jha, A. and Tafjord, Oyvind and Schwenk, Dustin and Walsh, Evan Pete and Elazar, Yanai and Lo, Kyle and Groeneveld, Dirk and Beltagy, Iz and Hajishirzi, Hanna and Smith, Noah A. and Richardson, Kyle and Dodge, Jesse}, booktitle = {NeurIPS (Datasets and Benchmarks)}, month = dec, title = {Paloma: A Benchmark for Evaluating Language Model Fit}, url = {https://proceedings.neurips.cc/paper_files/paper/2024/hash/760b2d94398aa61468aa3bc11506d9ea-Abstract-Datasets_and_Benchmarks_Track.html}, year = {2024} }


















2023
-
 Open Domain Multi-document Summarization: A Comprehensive Study of Model Brittleness under RetrievalJohn Giorgi, Luca Soldaini, Bo Wang, Gary Bader, Kyle Lo, Lucy Wang, and Arman CohanIn Findings of EMNLP, Dec 2023
Open Domain Multi-document Summarization: A Comprehensive Study of Model Brittleness under RetrievalJohn Giorgi, Luca Soldaini, Bo Wang, Gary Bader, Kyle Lo, Lucy Wang, and Arman CohanIn Findings of EMNLP, Dec 2023Multi-document summarization (MDS) assumes a set of topic-related documents are provided as input. In practice, this document set is not always available; it would need to be retrieved given an information need, i.e. a question or topic statement, a setting we dub “open-domain’ MDS. We study this more challenging setting by formalizing the task and bootstrapping it using existing datasets, retrievers and summarizers. Via extensive automatic and human evaluation, we determine: (1) state-of-the-art summarizers suffer large reductions in performance when applied to open-domain MDS, (2) additional training in the open-domain setting can reduce this sensitivity to imperfect retrieval, and (3) summarizers are insensitive to the retrieval of duplicate documents and the order of retrieved documents, but highly sensitive to other errors, like the retrieval of irrelevant documents. Based on our results, we provide practical guidelines to enable future work on open-domain MDS, e.g. how to choose the number of retrieved documents to summarize. Our results suggest that new retrieval and summarization methods and annotated resources for training and evaluation are necessary for further progress in the open-domain setting.
@inproceedings{Giorgi2023OpenDomainMulti, author = {Giorgi, John and Soldaini, Luca and Wang, Bo and Bader, Gary and Lo, Kyle and Wang, Lucy and Cohan, Arman}, booktitle = {Findings of EMNLP}, doi = {10.18653/v1/2023.findings-emnlp.549}, month = dec, title = {Open Domain Multi-document Summarization: A Comprehensive Study of Model Brittleness under Retrieval}, url = {https://aclanthology.org/2023.findings-emnlp.549}, year = {2023} } -
 Decomposing Complex Queries for Tip-of-the-tongue RetrievalKevin Lin, Kyle Lo, Joseph Gonzalez, and Dan KleinIn Findings of EMNLP, Dec 2023
Decomposing Complex Queries for Tip-of-the-tongue RetrievalKevin Lin, Kyle Lo, Joseph Gonzalez, and Dan KleinIn Findings of EMNLP, Dec 2023When re-finding items, users who forget or are uncertain about identifying details often rely on creative strategies for expressing their information needs—complex queries that describe content elements (e.g., book characters or events), information beyond the document text (e.g., descriptions of book covers), or personal context (e.g., when they read a book). Standard retrieval models that rely on lexical or semantic overlap between query and document text are challenged in such retrieval settings, known as tip-of-the-tongue (TOT) retrieval. We introduce a simple but effective framework for handling such complex queries by decomposing the query with an LLM into individual clues routing those as subqueries to specialized retrievers, and ensembling the results. Our approach takes advantage of off-the-shelf retrievers (e.g., CLIP for retrieving images of book covers) or incorporate retriever-specific logic (e.g., date constraints). We show that our framework incorporating query decomposition into retrievers can improve gold book recall up to 6% absolute gain for Recall@5 on a new collection of 14,441 real-world query-book pairs from an online community for resolving TOT inquiries.
@inproceedings{Lin2023DecomposingComplexQueries, author = {Lin, Kevin and Lo, Kyle and Gonzalez, Joseph and Klein, Dan}, booktitle = {Findings of EMNLP}, doi = {10.18653/v1/2023.findings-emnlp.367}, month = dec, title = {Decomposing Complex Queries for Tip-of-the-tongue Retrieval}, url = {https://aclanthology.org/2023.findings-emnlp.367}, year = {2023} } -
 PaperMage: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific DocumentsKyle Lo, Zejiang Shen, Benjamin Newman, Joseph Chang, Russell Authur, Erin Bransom, Stefan Candra, and 10 more authorsIn EMNLP System Demonstrations, Dec 2023
PaperMage: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific DocumentsKyle Lo, Zejiang Shen, Benjamin Newman, Joseph Chang, Russell Authur, Erin Bransom, Stefan Candra, and 10 more authorsIn EMNLP System Demonstrations, Dec 2023Best Paper Award
Despite growing interest in applying natural language processing (NLP) and computer vision (CV) models to the scholarly domain, scientific documents remain challenging to work with. They’re often in difficult-to-use PDF formats, and the ecosystem of models to process them is fragmented and incomplete. We introduce PaperMage, an open-source Python toolkit for analyzing and processing visually-rich, structured scientific documents. PaperMage offers clean and intuitive abstractions for seamlessly representing and manipulating both textual and visual document elements. PaperMage achieves this by integrating disparate state-of-the-art NLP and CV models into a unified framework, and provides turn-key recipes for common scientific document processing use-cases. PaperMage has powered multiple research prototypes of AI applications over scientific documents, along with Semantic Scholar’s large-scale production system for processing millions of PDFs. GitHub: https://github.com/allenai/papermage
@inproceedings{Lo2023PapermageUnifiedToolkit, author = {Lo, Kyle and Shen, Zejiang and Newman, Benjamin and Chang, Joseph and Authur, Russell and Bransom, Erin and Candra, Stefan and Chandrasekhar, Yoganand and Huff, Regan and Kuehl, Bailey and Singh, Amanpreet and Wilhelm, Chris and Zamarron, Angele and Hearst, Marti A. and Weld, Daniel and Downey, Doug and Soldaini, Luca}, booktitle = {EMNLP System Demonstrations}, doi = {10.18653/v1/2023.emnlp-demo.45}, month = dec, title = {{P}aper{M}age: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific Documents}, url = {https://aclanthology.org/2023.emnlp-demo.45}, year = {2023} } -
 A Question Answering Framework for Decontextualizing User-facing Snippets from Scientific DocumentsBenjamin Newman, Luca Soldaini, Raymond Fok, Arman Cohan, and Kyle LoIn EMNLP, Dec 2023
A Question Answering Framework for Decontextualizing User-facing Snippets from Scientific DocumentsBenjamin Newman, Luca Soldaini, Raymond Fok, Arman Cohan, and Kyle LoIn EMNLP, Dec 2023Many real-world applications (e.g., note taking, search) require extracting a sentence or paragraph from a document and showing that snippet to a human outside of the source document. Yet, users may find snippets difficult to understand as they lack context from the original document. In this work, we use language models to rewrite snippets from scientific documents to be read on their own. First, we define the requirements and challenges for this user-facing decontextualization task, such as clarifying where edits occur and handling references to other documents. Second, we propose a framework that decomposes the task into three stages: question generation, question answering, and rewriting. Using this framework, we collect gold decontextualizations from experienced scientific article readers. We then conduct a range of experiments across state-of-the-art commercial and open-source language models to identify how to best provide missing-but-relevant information to models for our task. Finally, we develop QaDecontext, a simple prompting strategy inspired by our framework that improves over end-to-end prompting. We conclude with analysis that finds, while rewriting is easy, question generation and answering remain challenging for today’s models.
@inproceedings{Newman2023QuestionAnsweringFramework, author = {Newman, Benjamin and Soldaini, Luca and Fok, Raymond and Cohan, Arman and Lo, Kyle}, booktitle = {EMNLP}, doi = {10.18653/v1/2023.emnlp-main.193}, month = dec, title = {A Question Answering Framework for Decontextualizing User-facing Snippets from Scientific Documents}, url = {https://aclanthology.org/2023.emnlp-main.193}, year = {2023} } -
 Back to Basics: A Simple Recipe for Improving Out-of-Domain Retrieval in Dense EncodersHyunji Lee, Luca Soldaini, Arman Cohan, Minjoon Seo, and Kyle LoArXiv, Nov 2023
Back to Basics: A Simple Recipe for Improving Out-of-Domain Retrieval in Dense EncodersHyunji Lee, Luca Soldaini, Arman Cohan, Minjoon Seo, and Kyle LoArXiv, Nov 2023Prevailing research practice today often relies on training dense retrievers on existing large datasets such as MSMARCO and then experimenting with ways to improve zero-shot generalization capabilities to unseen domains. While prior work has tackled this challenge through resource-intensive steps such as data augmentation, architectural modifications, increasing model size, or even further base model pretraining, comparatively little investigation has examined whether the training procedures themselves can be improved to yield better generalization capabilities in the resulting models. In this work, we recommend a simple recipe for training dense encoders: Train on MSMARCO with parameter-efficient methods, such as LoRA, and opt for using in-batch negatives unless given well-constructed hard negatives. We validate these recommendations using the BEIR benchmark and find results are persistent across choice of dense encoder and base model size and are complementary to other resource-intensive strategies for out-of-domain generalization such as architectural modifications or additional pretraining. We hope that this thorough and impartial study around various training techniques, which augments other resource-intensive methods, offers practical insights for developing a dense retrieval model that effectively generalizes, even when trained on a single dataset.
@article{Lee2023BackTB, author = {Lee, Hyunji and Soldaini, Luca and Cohan, Arman and Seo, Minjoon and Lo, Kyle}, journal = {ArXiv}, month = nov, title = {Back to Basics: A Simple Recipe for Improving Out-of-Domain Retrieval in Dense Encoders}, url = {https://arxiv.org/abs/2311.09765}, year = {2023} } -
 The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing PracticesHancheng Cao, Jesse Dodge, Kyle Lo, Daniel A. McFarland, and Lucy Lu WangArXiv, Oct 2023
The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing PracticesHancheng Cao, Jesse Dodge, Kyle Lo, Daniel A. McFarland, and Lucy Lu WangArXiv, Oct 2023In recent years, funding agencies and journals increasingly advocate for open science practices (e.g. data and method sharing) to improve the transparency, access, and reproducibility of science. However, quantifying these practices at scale has proven difficult. In this work, we leverage a large-scale dataset of 1.1M papers from arXiv that are representative of the fields of physics, math, and computer science to analyze the adoption of data and method link-sharing practices over time and their impact on article reception. To identify links to data and methods, we train a neural text classification model to automatically classify URL types based on contextual mentions in papers. We find evidence that the practice of link-sharing to methods and data is spreading as more papers include such URLs over time. Reproducibility efforts may also be spreading because the same links are being increasingly reused across papers (especially in computer science); and these links are increasingly concentrated within fewer web domains (e.g. Github) over time. Lastly, articles that share data and method links receive increased recognition in terms of citation count, with a stronger effect when the shared links are active (rather than defunct). Together, these findings demonstrate the increased spread and perceived value of data and method sharing practices in open science.
@article{Cao2023TheRO, author = {Cao, Hancheng and Dodge, Jesse and Lo, Kyle and McFarland, Daniel A. and Wang, Lucy Lu}, journal = {ArXiv}, month = oct, title = {The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing Practices}, url = {https://arxiv.org/abs/2310.03193}, year = {2023} } -
 When do Generative Query and Document Expansions Fail? A Comprehensive Study Across Methods, Retrievers, and DatasetsOrion Weller, Kyle Lo, David Wadden, Dawn J Lawrie, Benjamin Van Durme, Arman Cohan, and Luca SoldainiArXiv, Sep 2023
When do Generative Query and Document Expansions Fail? A Comprehensive Study Across Methods, Retrievers, and DatasetsOrion Weller, Kyle Lo, David Wadden, Dawn J Lawrie, Benjamin Van Durme, Arman Cohan, and Luca SoldainiArXiv, Sep 2023Using large language models (LMs) for query or document expansion can improve generalization in information retrieval. However, it is unknown whether these techniques are universally beneficial or only effective in specific settings, such as for particular retrieval models, dataset domains, or query types. To answer this, we conduct the first comprehensive analysis of LM-based expansion. We find that there exists a strong negative correlation between retriever performance and gains from expansion: expansion improves scores for weaker models, but generally harms stronger models. We show this trend holds across a set of eleven expansion techniques, twelve datasets with diverse distribution shifts, and twenty-four retrieval models. Through qualitative error analysis, we hypothesize that although expansions provide extra information (potentially improving recall), they add additional noise that makes it difficult to discern between the top relevant documents (thus introducing false positives). Our results suggest the following recipe: use expansions for weaker models or when the target dataset significantly differs from training corpus in format; otherwise, avoid expansions to keep the relevance signal clear.
@article{Weller2023WhenDG, author = {Weller, Orion and Lo, Kyle and Wadden, David and Lawrie, Dawn J and Durme, Benjamin Van and Cohan, Arman and Soldaini, Luca}, journal = {ArXiv}, month = sep, title = {When do Generative Query and Document Expansions Fail? A Comprehensive Study Across Methods, Retrievers, and Datasets}, url = {https://arxiv.org/abs/2309.08541}, year = {2023} } -
 Are Layout-Infused Language Models Robust to Layout Distribution Shifts? A Case Study with Scientific DocumentsCatherine Chen, Zejiang Shen, Dan Klein, Gabriel Stanovsky, Doug Downey, and Kyle LoIn Findings of ACL, Jul 2023
Are Layout-Infused Language Models Robust to Layout Distribution Shifts? A Case Study with Scientific DocumentsCatherine Chen, Zejiang Shen, Dan Klein, Gabriel Stanovsky, Doug Downey, and Kyle LoIn Findings of ACL, Jul 2023Recent work has shown that infusing layout features into language models (LMs) improves processing of visually-rich documents such as scientific papers. Layout-infused LMs are often evaluated on documents with familiar layout features (e.g., papers from the same publisher), but in practice models encounter documents with unfamiliar distributions of layout features, such as new combinations of text sizes and styles, or new spatial configurations of textual elements. In this work we test whether layout-infused LMs are robust to layout distribution shifts. As a case study we use the task of scientific document structure recovery, segmenting a scientific paper into its structural categories (e.g., “title”, “caption”, “reference”). To emulate distribution shifts that occur in practice we re-partition the GROTOAP2 dataset. We find that under layout distribution shifts model performance degrades by up to 20 F1. Simple training strategies, such as increasing training diversity, can reduce this degradation by over 35% relative F1; however, models fail to reach in-distribution performance in any tested out-of-distribution conditions. This work highlights the need to consider layout distribution shifts during model evaluation, and presents a methodology for conducting such evaluations.
@inproceedings{Chen2023LayoutInfusedLanguage, author = {Chen, Catherine and Shen, Zejiang and Klein, Dan and Stanovsky, Gabriel and Downey, Doug and Lo, Kyle}, booktitle = {Findings of ACL}, doi = {10.18653/v1/2023.findings-acl.844}, month = jul, title = {Are Layout-Infused Language Models Robust to Layout Distribution Shifts? A Case Study with Scientific Documents}, url = {https://aclanthology.org/2023.findings-acl.844}, year = {2023} } -
 Efficiency Pentathlon: A Standardized Arena for Efficiency EvaluationHao Peng, Qingqing Cao, Jesse Dodge, Matthew E. Peters, Jared Fernandez, Tom Sherborne, Kyle Lo, and 7 more authorsArXiv, Jul 2023
Efficiency Pentathlon: A Standardized Arena for Efficiency EvaluationHao Peng, Qingqing Cao, Jesse Dodge, Matthew E. Peters, Jared Fernandez, Tom Sherborne, Kyle Lo, and 7 more authorsArXiv, Jul 2023Rising computational demands of modern natural language processing (NLP) systems have increased the barrier to entry for cutting-edge research while posing serious environmental concerns. Yet, progress on model efficiency has been impeded by practical challenges in model evaluation and comparison. For example, hardware is challenging to control due to disparate levels of accessibility across different institutions. Moreover, improvements in metrics such as FLOPs often fail to translate to progress in real-world applications. In response, we introduce Pentathlon, a benchmark for holistic and realistic evaluation of model efficiency. Pentathlon focuses on inference, which accounts for a majority of the compute in a model’s lifecycle. It offers a strictly-controlled hardware platform, and is designed to mirror real-world applications scenarios. It incorporates a suite of metrics that target different aspects of efficiency, including latency, throughput, memory overhead, and energy consumption. Pentathlon also comes with a software library that can be seamlessly integrated into any codebase and enable evaluation. As a standardized and centralized evaluation platform, Pentathlon can drastically reduce the workload to make fair and reproducible efficiency comparisons. While initially focused on natural language processing (NLP) models, Pentathlon is designed to allow flexible extension to other fields. We envision Pentathlon will stimulate algorithmic innovations in building efficient models, and foster an increased awareness of the social and environmental implications in the development of future-generation NLP models.
@article{Peng2023EfficiencyPA, author = {Peng, Hao and Cao, Qingqing and Dodge, Jesse and Peters, Matthew E. and Fernandez, Jared and Sherborne, Tom and Lo, Kyle and Skjonsberg, Sam and Strubell, Emma and Plessas, Darrell and Beltagy, Iz and Walsh, Evan Pete and Smith, Noah and Hajishirzi, Hanna}, journal = {ArXiv}, month = jul, title = {Efficiency Pentathlon: A Standardized Arena for Efficiency Evaluation}, url = {https://arxiv.org/abs/2307.09701}, year = {2023} } -
 LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form SummarizationKalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, and Kyle LoIn EACL, May 2023
LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form SummarizationKalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, and Kyle LoIn EACL, May 2023Outstanding Paper Award
While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall’s tau using 50% judgements). We release our human judgments, annotation templates, and software as a Python library for future research.
@inproceedings{Krishna2023LongevalGuidelinesHuman, author = {Krishna, Kalpesh and Bransom, Erin and Kuehl, Bailey and Iyyer, Mohit and Dasigi, Pradeep and Cohan, Arman and Lo, Kyle}, booktitle = {EACL}, doi = {10.18653/v1/2023.eacl-main.121}, month = may, title = {{L}ong{E}val: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization}, url = {https://aclanthology.org/2023.eacl-main.121}, year = {2023} } -
 Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition ExtractionAnna Martin-Boyle, Andrew Head, Kyle Lo, Risham Sidhu, Marti A. Hearst, and Dongyeop KangArXiv, May 2023
Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition ExtractionAnna Martin-Boyle, Andrew Head, Kyle Lo, Risham Sidhu, Marti A. Hearst, and Dongyeop KangArXiv, May 2023Mathematical symbol definition extraction is important for improving scholarly reading interfaces and scholarly information extraction (IE). However, the task poses several challenges: math symbols are difficult to process as they are not composed of natural language morphemes; and scholarly papers often contain sentences that require resolving complex coordinate structures. We present SymDef, an English language dataset of 5,927 sentences from full-text scientific papers where each sentence is annotated with all mathematical symbols linked with their corresponding definitions. This dataset focuses specifically on complex coordination structures such as "respectively" constructions, which often contain overlapping definition spans. We also introduce a new definition extraction method that masks mathematical symbols, creates a copy of each sentence for each symbol, specifies a target symbol, and predicts its corresponding definition spans using slot filling. Our experiments show that our definition extraction model significantly outperforms RoBERTa and other strong IE baseline systems by 10.9 points with a macro F1 score of 84.82. With our dataset and model, we can detect complex definitions in scholarly documents to make scientific writing more readable.
@article{MartinBoyle2023ComplexMS, author = {Martin-Boyle, Anna and Head, Andrew and Lo, Kyle and Sidhu, Risham and Hearst, Marti A. and Kang, Dongyeop}, journal = {ArXiv}, month = may, title = {Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition Extraction}, url = {https://arxiv.org/abs/2305.14660}, volume = {2305.14660}, year = {2023} } -
 CiteSee: Augmenting Citations in Scientific Papers with Persistent and Personalized Historical ContextJoseph Chee Chang, Amy X. Zhang, Jonathan Bragg, Andrew Head, Kyle Lo, Doug Downey, and Daniel S. WeldIn CHI, Apr 2023
CiteSee: Augmenting Citations in Scientific Papers with Persistent and Personalized Historical ContextJoseph Chee Chang, Amy X. Zhang, Jonathan Bragg, Andrew Head, Kyle Lo, Doug Downey, and Daniel S. WeldIn CHI, Apr 2023Best Paper Award
When reading a scholarly article, inline citations help researchers contextualize the current article and discover relevant prior work. However, it can be challenging to prioritize and make sense of the hundreds of citations encountered during literature reviews. This paper introduces CiteSee, a paper reading tool that leverages a user’s publishing, reading, and saving activities to provide personalized visual augmentations and context around citations. First, CiteSee connects the current paper to familiar contexts by surfacing known citations a user had cited or opened. Second, CiteSee helps users prioritize their exploration by highlighting relevant but unknown citations based on saving and reading history. We conducted a lab study that suggests CiteSee is significantly more effective for paper discovery than three baselines. A field deployment study shows CiteSee helps participants keep track of their explorations and leads to better situational awareness and increased paper discovery via inline citation when conducting real-world literature reviews.
@inproceedings{Chang2023CiteseeAugmentingCitations, author = {Chang, Joseph Chee and Zhang, Amy X. and Bragg, Jonathan and Head, Andrew and Lo, Kyle and Downey, Doug and Weld, Daniel S.}, booktitle = {CHI}, doi = {10.1145/3544548.3580847}, month = apr, title = {CiteSee: Augmenting Citations in Scientific Papers with Persistent and Personalized Historical Context}, url = {https://doi.org/10.1145/3544548.3580847}, year = {2023} } -
 Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language ProcessingTal August, Lucy Lu Wang, Jonathan Bragg, Marti A. Hearst, Andrew Head, and Kyle LoACM Transactions of Computer-Human Interaction (TOCHI), Apr 2023
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language ProcessingTal August, Lucy Lu Wang, Jonathan Bragg, Marti A. Hearst, Andrew Head, and Kyle LoACM Transactions of Computer-Human Interaction (TOCHI), Apr 2023When seeking information not covered in patient-friendly documents, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we explore four features enabled by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guides readers to answering passages, and plain language summaries of those passages. We embody these features into a prototype system, Paper Plain. We evaluate Paper Plain, finding that participants who used the prototype system had an easier time reading research papers without a loss in paper comprehension compared to those who used a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.
@article{August2023PaperPlainMaking, author = {August, Tal and Wang, Lucy Lu and Bragg, Jonathan and Hearst, Marti A. and Head, Andrew and Lo, Kyle}, doi = {10.1145/3589955}, journal = {ACM Transactions of Computer-Human Interaction (TOCHI)}, month = apr, title = {Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing}, url = {https://doi.org/10.1145/3589955}, volume = {30}, year = {2023} } -
 Beyond Summarization: Designing AI Support for Real-World Expository Writing TasksZejiang Shen, Tal August, Pao Siangliulue, Kyle Lo, Jonathan Bragg, Jeff Hammerbacher, Doug Downey, and 2 more authorsIn Intelligent and Interactive Writing Assistants (In2Writing) Workshop, Apr 2023
Beyond Summarization: Designing AI Support for Real-World Expository Writing TasksZejiang Shen, Tal August, Pao Siangliulue, Kyle Lo, Jonathan Bragg, Jeff Hammerbacher, Doug Downey, and 2 more authorsIn Intelligent and Interactive Writing Assistants (In2Writing) Workshop, Apr 2023Large language models have introduced exciting new opportunities and challenges in designing and developing new AI-assisted writing support tools. Recent work has shown that leveraging this new technology can transform writing in many scenarios such as ideation during creative writing, editing support, and summarization. However, AI-supported expository writing–including real-world tasks like scholars writing literature reviews or doctors writing progress notes–is relatively understudied. In this position paper, we argue that developing AI supports for expository writing has unique and exciting research challenges and can lead to high real-world impacts. We characterize expository writing as evidence-based and knowledge-generating: it contains summaries of external documents as well as new information or knowledge. It can be seen as the product of authors’ sensemaking process over a set of source documents, and the interplay between reading, reflection, and writing opens up new opportunities for designing AI support. We sketch three components for AI support design and discuss considerations for future research.
@inproceedings{Shen2023BeyondSD, author = {Shen, Zejiang and August, Tal and Siangliulue, Pao and Lo, Kyle and Bragg, Jonathan and Hammerbacher, Jeff and Downey, Doug and Chang, Joseph Chee and Sontag, David}, booktitle = {Intelligent and Interactive Writing Assistants (In2Writing) Workshop}, month = apr, title = {Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks}, url = {https://arxiv.org/abs/2304.02623}, volume = {2304.02623}, year = {2023} } -
 Scim: Intelligent Skimming Support for Scientific PapersRaymond Fok, Hita Kambhamettu, Luca Soldaini, Jonathan Bragg, Kyle Lo, Marti Hearst, Andrew Head, and 1 more authorIn IUI, Mar 2023
Scim: Intelligent Skimming Support for Scientific PapersRaymond Fok, Hita Kambhamettu, Luca Soldaini, Jonathan Bragg, Kyle Lo, Marti Hearst, Andrew Head, and 1 more authorIn IUI, Mar 2023Scholars need to keep up with an exponentially increasing flood of scientific papers. To aid this challenge, we introduce Scim, a novel intelligent interface that helps experienced researchers skim – or rapidly review – a paper to attain a cursory understanding of its contents. Scim supports the skimming process by highlighting salient paper contents in order to direct a reader’s attention. The system’s highlights are faceted by content type, evenly distributed across a paper, and have a density configurable by readers at both the global and local level. We evaluate Scim with both an in-lab usability study and a longitudinal diary study, revealing how its highlights facilitate the more efficient construction of a conceptualization of a paper. We conclude by discussing design considerations and tensions for the design of future intelligent skimming tools.
@inproceedings{Fok2023ScimIntelligentSkimming, author = {Fok, Raymond and Kambhamettu, Hita and Soldaini, Luca and Bragg, Jonathan and Lo, Kyle and Hearst, Marti and Head, Andrew and Weld, Daniel S}, booktitle = {IUI}, doi = {10.1145/3581641.3584034}, month = mar, title = {Scim: Intelligent Skimming Support for Scientific Papers}, url = {https://doi.org/10.1145/3581641.3584034}, year = {2023} } -
 LIMEADE: From AI Explanations to Advice TakingBenjamin Charles Germain Lee, Doug Downey, Kyle Lo, and Daniel S. WeldACM Transactions on Interactive Intelligent Systems, Mar 2023
LIMEADE: From AI Explanations to Advice TakingBenjamin Charles Germain Lee, Doug Downey, Kyle Lo, and Daniel S. WeldACM Transactions on Interactive Intelligent Systems, Mar 2023Research in human-centered AI has shown the benefits of systems that can explain their predictions. Methods that allow an AI to take advice from humans in response to explanations are similarly useful. While both capabilities are well-developed for transparent learning models (e.g., linear models and GA2Ms), and recent techniques (e.g., LIME and SHAP) can generate explanations for opaque models, little attention has been given to advice methods for opaque models. This paper introduces LIMEADE, the first general framework that translates both positive and negative advice (expressed using high-level vocabulary such as that employed by post-hoc explanations) into an update to an arbitrary, underlying opaque model. We demonstrate the generality of our approach with case studies on seventy real-world models across two broad domains: image classification and text recommendation. We show our method improves accuracy compared to a rigorous baseline on the image classification domains. For the text modality, we apply our framework to a neural recommender system for scientific papers on a public website; our user study shows that our framework leads to significantly higher perceived user control, trust, and satisfaction.
@article{Lee2023LimeadeAiExplanations, author = {Lee, Benjamin Charles Germain and Downey, Doug and Lo, Kyle and Weld, Daniel S.}, doi = {10.1145/3589345}, journal = {ACM Transactions on Interactive Intelligent Systems}, month = mar, title = {LIMEADE: From AI Explanations to Advice Taking}, url = {https://doi.org/10.1145/3589345}, volume = {13}, year = {2023} } -
 The Semantic Scholar Open Data PlatformRodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, and 41 more authorsArXiv, Jan 2023
The Semantic Scholar Open Data PlatformRodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, and 41 more authorsArXiv, Jan 2023The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
@article{Kinney2023TheSS, author = {Kinney, Rodney Michael and Anastasiades, Chloe and Authur, Russell and Beltagy, Iz and Bragg, Jonathan and Buraczynski, Alexandra and Cachola, Isabel and Candra, Stefan and Chandrasekhar, Yoganand and Cohan, Arman and Crawford, Miles and Downey, Doug and Dunkelberger, Jason and Etzioni, Oren and Evans, Rob and Feldman, Sergey and Gorney, Joseph and Graham, David W. and Hu, F.Q. and Huff, Regan and King, Daniel and Kohlmeier, Sebastian and Kuehl, Bailey and Langan, Michael and Lin, Daniel and Liu, Haokun and Lo, Kyle and Lochner, Jaron and MacMillan, Kelsey and Murray, Tyler and Newell, Christopher and Rao, Smita and Rohatgi, Shaurya and Sayre, Paul L and Shen, Zejiang and Singh, Amanpreet and Soldaini, Luca and Subramanian, Shivashankar and Tanaka, A. and Wade, Alex D and Wagner, Linda M. and Wang, Lucy Lu and Wilhelm, Christopher and Wu, Caroline and Yang, Jiangjiang and Zamarron, Angele and van Zuylen, Madeleine and Weld, Daniel S.}, journal = {ArXiv}, month = jan, title = {The Semantic Scholar Open Data Platform}, url = {https://arxiv.org/abs/2301.10140}, volume = {2301.10140}, year = {2023} } -
 peS2o (Pretraining Efficiently on S2ORC) DatasetLuca Soldaini, and Kyle LoAllen Institute for AI, Tech. Rep, Jun 2023
peS2o (Pretraining Efficiently on S2ORC) DatasetLuca Soldaini, and Kyle LoAllen Institute for AI, Tech. Rep, Jun 2023The peS2o dataset is a collection of 40M creative open-access academic papers, cleaned, filtered, and formatted for pre-training of language models. It is derived from the Semantic Scholar Open Research Corpus (Lo et al, 2020), or S2ORC.
@article{Soldaini2023Pes2opretrainingEfficiently, author = {Soldaini, Luca and Lo, Kyle}, journal = {Allen Institute for AI, Tech. Rep}, month = jun, title = {peS2o (Pretraining Efficiently on S2ORC) Dataset}, url = {https://huggingface.co/datasets/allenai/peS2o}, year = {2023} }

















2022
-
 SciFact-Open: Towards open-domain scientific claim verificationDavid Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Iz Beltagy, Lucy Lu Wang, and Hannaneh HajishirziIn Findings of EMNLP, Dec 2022
SciFact-Open: Towards open-domain scientific claim verificationDavid Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Iz Beltagy, Lucy Lu Wang, and Hannaneh HajishirziIn Findings of EMNLP, Dec 2022While research on scientific claim verification has led to the development of powerful systems that appear to approach human performance, these approaches have yet to be tested in a realistic setting against large corpora of scientific literature. Moving to this open-domain evaluation setting, however, poses unique challenges; in particular, it is infeasible to exhaustively annotate all evidence documents. In this work, we present SciFact-Open, a new test collection designed to evaluate the performance of scientific claim verification systems on a corpus of 500K research abstracts. Drawing upon pooling techniques from information retrieval, we collect evidence for scientific claims by pooling and annotating the top predictions of four state-of-the-art scientific claim verification models. We find that systems developed on smaller corpora struggle to generalize to SciFact-Open, exhibiting performance drops of at least 15 F1. In addition, analysis of the evidence in SciFact-Open reveals interesting phenomena likely to appear when claim verification systems are deployed in practice, e.g., cases where the evidence supports only a special case of the claim. Our dataset is available at https://github.com/dwadden/scifact-open.
@inproceedings{Wadden2022ScifactOpenTowards, author = {Wadden, David and Lo, Kyle and Kuehl, Bailey and Cohan, Arman and Beltagy, Iz and Wang, Lucy Lu and Hajishirzi, Hannaneh}, booktitle = {Findings of EMNLP}, doi = {10.18653/v1/2022.findings-emnlp.347}, month = dec, title = {{S}ci{F}act-Open: Towards open-domain scientific claim verification}, url = {https://aclanthology.org/2022.findings-emnlp.347}, year = {2022} } -
 BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelTeven Le Scao, Angela Fan, Christopher Akiki, Elizabeth-Jane Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, and 383 more authorsArXiv, Nov 2022
BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelTeven Le Scao, Angela Fan, Christopher Akiki, Elizabeth-Jane Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, and 383 more authorsArXiv, Nov 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
@article{Scao2022BLOOMA1, author = {Scao, Teven Le and Fan, Angela and Akiki, Christopher and Pavlick, Elizabeth-Jane and Ili'c, Suzana and Hesslow, Daniel and Castagn'e, Roman and Luccioni, Alexandra Sasha and Yvon, Franccois and Gall{\'e}, Matthias and Tow, Jonathan and Rush, Alexander M. and Biderman, Stella Rose and Webson, Albert and Ammanamanchi, Pawan Sasanka and Wang, Thomas and Sagot, Beno{\i}t and Muennighoff, Niklas and del Moral, Albert Villanova and Ruwase, Olatunji and Bawden, Rachel and Bekman, Stas and McMillan-Major, Angelina and Beltagy, Iz and Nguyen, Huu and Saulnier, Lucile and Tan, Samson and Suarez, Pedro Ortiz and Sanh, Victor and Laurenccon, Hugo and Jernite, Yacine and Launay, Julien and Mitchell, Margaret and Raffel, Colin and Gokaslan, Aaron and Simhi, Adi and Etxabe, Aitor Soroa and Aji, Alham Fikri and Alfassy, Amit and Rogers, Anna and Nitzav, Ariel Kreisberg and Xu, Canwen and Mou, Chenghao and Emezue, Chris C. and Klamm, Christopher and Leong, Colin and van Strien, Daniel Alexander and Adelani, David Ifeoluwa and Radev, Dragomir R. and Ponferrada, Eduardo G. and Levkovizh, Efrat and Kim, Ethan and Natan, Eyal Bar and Toni, Francesco De and Dupont, G{\'e}rard and Kruszewski, Germ{\'a}n and Pistilli, Giada and ElSahar, Hady and Benyamina, Hamza and Tran, Hieu and Yu, Ian and Abdulmumin, Idris and Johnson, Isaac and Gonzalez-Dios, Itziar and de la Rosa, Javier and Chim, Jenny and Dodge, Jesse and Zhu, Jian and Chang, Jonathan and Frohberg, Jorg and Tobing, Josephine L. and Bhattacharjee, Joydeep and Almubarak, Khalid and Chen, Kimbo and Lo, Kyle and von Werra, Leandro and Weber, Leon and Phan, Long and Allal, Loubna Ben and Tanguy, Ludovic and Dey, Manan and Mu{\~n}oz, Manuel Romero and Masoud, Maraim and Grandury, Mar'ia and vSavsko, Mario and Huang, Max and Coavoux, Maximin and Singh, Mayank and Jiang, Mike Tian-Jian and Vu, Minh Chien and Jauhar, Mohammad Ali and Ghaleb, Mustafa and Subramani, Nishant and Kassner, Nora and Khamis, Nurulaqilla and Nguyen, Olivier and Espejel, Omar and de Gibert, Ona and Villegas, Paulo and Henderson, Peter and Colombo, Pierre and Amuok, Priscilla and Lhoest, Quentin and Harliman, Rheza and Bommasani, Rishi and L'opez, Roberto and Ribeiro, R. and Osei, Salomey and Pyysalo, Sampo and Nagel, Sebastian and Bose, Shamik and Muhammad, Shamsuddeen Hassan and Sharma, Shanya and Longpre, S. and Nikpoor, Somaieh and Silberberg, Stanislav and Pai, Suhas and Zink, Sydney and Torrent, Tiago Timponi and Schick, Timo and Thrush, Tristan and Danchev, Valentin and Nikoulina, Vassilina and Laippala, Veronika and Lepercq, Violette and Prabhu, Vrinda and Alyafeai, Zaid and Talat, Zeerak and Raja, Arun and Heinzerling, Benjamin and Si, Chenglei and Salesky, Elizabeth and Mielke, Sabrina J. and Lee, Wilson Y. and Sharma, Abheesht and Santilli, Andrea and Chaffin, Antoine and Stiegler, Arnaud and Datta, Debajyoti and Szczechla, Eliza and Chhablani, Gunjan and Wang, Han and Pandey, Harshit and Strobelt, Hendrik and Fries, Jason Alan and Rozen, Jos and Gao, Leo and Sutawika, Lintang and Bari, M Saiful and Al-shaibani, Maged S. and Manica, Matteo and Nayak, Nihal V. and Teehan, Ryan and Albanie, Samuel and Shen, Sheng and Ben-David, Srulik and Bach, Stephen H. and Kim, Taewoon and Bers, Tali and F{\'e}vry, Thibault and Neeraj, Trishala and Thakker, Urmish and Raunak, Vikas and Tang, Xiang and Yong, Zheng Xin and Sun, Zhiqing and Brody, Shaked and Uri, Y and Tojarieh, Hadar and Roberts, Adam and Chung, Hyung Won and Tae, Jaesung and Phang, Jason and Press, Ofir and Li, Conglong and Narayanan, Deepak and Bourfoune, Hatim and Casper, Jared and Rasley, Jeff and Ryabinin, Max and Mishra, Mayank and Zhang, Minjia and Shoeybi, Mohammad and Peyrounette, Myriam and Patry, Nicolas and Tazi, Nouamane and Sanseviero, Omar and von Platen, Patrick and Cornette, Pierre and Lavall'ee, Pierre Franccois and Lacroix, R{\'e}mi and Rajbhandari, Samyam and Gandhi, Sanchit and Smith, Shaden and Requena, St{\'e}phane and Patil, Suraj and Dettmers, Tim and Baruwa, Ahmed and Singh, Amanpreet and Cheveleva, Anastasia and Ligozat, Anne-Laure and Subramonian, Arjun and N'ev'eol, Aur'elie and Lovering, Charles and Garrette, Daniel H and Tunuguntla, Deepak R. and Reiter, Ehud and Taktasheva, Ekaterina and Voloshina, Ekaterina and Bogdanov, Eli and Winata, Genta Indra and Schoelkopf, Hailey and Kalo, Jan-Christoph and Novikova, Jekaterina and Forde, Jessica Zosa and Clive, Jordan and Kasai, Jungo and Kawamura, Ken and Hazan, Liam and Carpuat, Marine and Clinciu, Miruna and Kim, Najoung and Cheng, Newton and Serikov, Oleg and Antverg, Omer and van der Wal, Oskar and Zhang, Rui and Zhang, Ruochen and Gehrmann, Sebastian and Pais, S. Osher and Shavrina, Tatiana and Scialom, Thomas and Yun, Tian and Limisiewicz, Tomasz and Rieser, Verena and Protasov, Vitaly and Mikhailov, Vladislav and Pruksachatkun, Yada and Belinkov, Yonatan and Bamberger, Zachary and Kasner, Zdenvek and Rueda, Alice and Pestana, Amanda and Feizpour, Amir and Khan, Ammar and Faranak, Amy and Santos, Ananda Santa Rosa and Hevia, Anthony and Unldreaj, Antigona and Aghagol, Arash and Abdollahi, Arezoo and Tammour, Aycha and HajiHosseini, Azadeh and Behroozi, Bahareh and Ajibade, Benjamin Olusola and Saxena, Bharat Kumar and Ferrandis, Carlos Mu{\~n}oz and Contractor, Danish and Lansky, David M. and David, Davis and Kiela, Douwe and Nguyen, Duong Anh and Tan, Edward and Baylor, Emily and Ozoani, Ezinwanne and Mirza, Fatim T and Ononiwu, Frankline and Rezanejad, Habib and Jones, H.A. and Bhattacharya, Indrani and Solaiman, Irene and Sedenko, Irina and Nejadgholi, Isar and Passmore, J. Lawrence and Seltzer, Joshua and Sanz, Julio Bonis and Fort, Karen and Dutra, L{\'i}via Macedo and Samagaio, Mairon and Elbadri, Maraim and Mieskes, Margot and Gerchick, Marissa and Akinlolu, Martha and McKenna, Michael and Qiu, Mike and Ghauri, M. K. K. and Burynok, Mykola and Abrar, Nafis and Rajani, Nazneen and Elkott, Nour and Fahmy, Nourhan and Samuel, Olanrewaju Modupe and An, Ran and Kromann, R. P. and Hao, Ryan and Alizadeh, Samira and Shubber, Sarmad and Wang, Silas L. and Roy, Sourav and Viguier, Sylvain and Le, Thanh-Cong and Oyebade, Tobi and Le, Trieu Nguyen Hai and Yang, Yoyo and Nguyen, Zachary Kyle and Kashyap, Abhinav Ramesh and Palasciano, Alfredo and Callahan, Alison and Shukla, Anima and Miranda-Escalada, Antonio and Singh, Ayush Kumar and Beilharz, Benjamin and Wang, Bo and de Brito, Caio Matheus Fonseca and Zhou, Chenxi and Jain, Chirag and Xu, Chuxin and Fourrier, Cl{\'e}mentine and Perin'an, Daniel Le'on and Molano, Daniel and Yu, Dian and Manjavacas, Enrique and Barth, Fabio and Fuhrimann, Florian and Altay, Gabriel and Bayrak, Giyaseddin and Burns, Gully A. and Vrabec, Helena U. and Bello, Iman I.B. and Dash, Isha and Kang, Ji Soo and Giorgi, John and Golde, Jonas and Posada, Jose David and Sivaraman, Karthi and Bulchandani, Lokesh and Liu, Lu and Shinzato, Luisa and de Bykhovetz, Madeleine Hahn and Takeuchi, Maiko and P{\`a}mies, Marc and Castillo, Mar{\'i}a Andrea and Nezhurina, Marianna and Sanger, Mario and Samwald, Matthias and Cullan, Michael and Weinberg, Michael and Wolf, M and Mihaljcic, Mina and Liu, Minna and Freidank, Moritz and Kang, Myungsun and Seelam, Natasha and Dahlberg, Nathan and Broad, Nicholas Michio and Muellner, Nikolaus and Fung, Pascale and Haller, Patricia and Chandrasekhar, R. and Eisenberg, R. and Martin, Robert and Canalli, Rodrigo L. and Su, Rosaline and Su, Ruisi and Cahyawijaya, Samuel and Garda, Samuele and Deshmukh, Shlok S and Mishra, Shubhanshu and Kiblawi, Sid and Ott, Simon and Sang-aroonsiri, Sinee and Kumar, Srishti and Schweter, Stefan and Bharati, Sushil Pratap and Laud, T. A. and Gigant, Th'eo and Kainuma, Tomoya and Kusa, Wojciech and Labrak, Yanis and Bajaj, Yashasvi and Venkatraman, Y. and Xu, Yifan and Xu, Ying and Xu, Yun-chao and Tan, Zhee Xao and Xie, Zhongli and Ye, Zifan and Bras, Mathilde and Belkada, Younes and Wolf, Thomas}, journal = {ArXiv}, month = nov, title = {BLOOM: A 176B-Parameter Open-Access Multilingual Language Model}, url = {https://arxiv.org/abs/2211.05100}, volume = {2211.05100}, year = {2022} } -
 Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple GranularitiesZejiang Shen, Kyle Lo, Lauren Yu, Nathan Dahlberg, Margo Schlanger, and Doug DowneyIn NeurIPS (Datasets and Benchmarks), Nov 2022
Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple GranularitiesZejiang Shen, Kyle Lo, Lauren Yu, Nathan Dahlberg, Margo Schlanger, and Doug DowneyIn NeurIPS (Datasets and Benchmarks), Nov 2022With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC, https://clearinghouse.net), which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further summarization research and to facilitate the development of applications to assist in the CRLC’s mission at https://multilexsum.github.io.
@inproceedings{Shen2022MultiLexsumReal, author = {Shen, Zejiang and Lo, Kyle and Yu, Lauren and Dahlberg, Nathan and Schlanger, Margo and Downey, Doug}, booktitle = {NeurIPS (Datasets and Benchmarks)}, month = nov, title = {Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple Granularities}, url = {https://openreview.net/forum?id=z1d8fUiS8Cr}, year = {2022} } -
 Overview of the Third Workshop on Scholarly Document ProcessingArman Cohan, Guy Feigenblat, Dayne Freitag, Tirthankar Ghosal, Drahomira Herrmannova, Petr Knoth, Kyle Lo, and 4 more authorsIn Scholarly Document Processing (SDP) Workshop, Oct 2022
Overview of the Third Workshop on Scholarly Document ProcessingArman Cohan, Guy Feigenblat, Dayne Freitag, Tirthankar Ghosal, Drahomira Herrmannova, Petr Knoth, Kyle Lo, and 4 more authorsIn Scholarly Document Processing (SDP) Workshop, Oct 2022With the ever-increasing pace of research and high volume of scholarly communication, scholars face a daunting task. Not only must they keep up with the growing literature in their own and related fields, scholars increasingly also need to rebut pseudo-science and disinformation. These needs have motivated an increasing focus on computational methods for enhancing search, summarization, and analysis of scholarly documents. However, the various strands of research on scholarly document processing remain fragmented. To reach out to the broader NLP and AI/ML community, pool distributed efforts in this area, and enable shared access to published research, we held the 3rd Workshop on Scholarly Document Processing (SDP) at COLING as a hybrid event (https://sdproc.org/2022/). The SDP workshop consisted of a research track, three invited talks and five Shared Tasks: 1) MSLR22: Multi-Document Summarization for Literature Reviews, 2) DAGPap22: Detecting automatically generated scientific papers, 3) SV-Ident 2022: Survey Variable Identification in Social Science Publications, 4) SKGG: Scholarly Knowledge Graph Generation, 5) MuP 2022: Multi Perspective Scientific Document Summarization. The program was geared towards NLP, information retrieval, and data mining for scholarly documents, with an emphasis on identifying and providing solutions to open challenges.
@inproceedings{Cohan2022OverviewThirdWorkshop, author = {Cohan, Arman and Feigenblat, Guy and Freitag, Dayne and Ghosal, Tirthankar and Herrmannova, Drahomira and Knoth, Petr and Lo, Kyle and Mayr, Philipp and Shmueli-Scheuer, Michal and de Waard, Anita and Wang, Lucy Lu}, booktitle = {Scholarly Document Processing (SDP) Workshop}, doi = {10.18653/v1/2022.sdp-1.1}, month = oct, title = {Overview of the Third Workshop on Scholarly Document Processing}, url = {https://aclanthology.org/2022.sdp-1.1}, year = {2022} } -
 Automatic question answering for multiple stakeholders, the epidemic question answering datasetTravis R. Goodwin, Dina Demner-Fushman, Kyle Lo, Lucy Lu Wang, Hoa T. Dang, and Ian M. SoboroffScientific Data, Jul 2022
Automatic question answering for multiple stakeholders, the epidemic question answering datasetTravis R. Goodwin, Dina Demner-Fushman, Kyle Lo, Lucy Lu Wang, Hoa T. Dang, and Ian M. SoboroffScientific Data, Jul 2022One of the effects of COVID-19 pandemic is a rapidly growing and changing stream of publications to inform clinicians, researchers, policy makers, and patients about the health, socio-economic, and cultural consequences of the pandemic. Managing this information stream manually is not feasible. Automatic Question Answering can quickly bring the most salient points to the user’s attention. Leveraging a collection of scientific articles, government websites, relevant news articles, curated social media posts, and questions asked by researchers, clinicians, and the general public, we developed a dataset to explore automatic Question Answering for multiple stakeholders. Analysis of questions asked by various stakeholders shows that while information needs of experts and the public may overlap, satisfactory answers to these questions often originate from different information sources or benefit from different approaches to answer generation. We believe that this dataset has the potential to support the development of question answering systems not only for epidemic questions, but for other domains with varying expertise such as legal or finance.
@article{Goodwin2022AutomaticQuestionAnswering, author = {Goodwin, Travis R. and Demner-Fushman, Dina and Lo, Kyle and Wang, Lucy Lu and Dang, Hoa T. and Soboroff, Ian M.}, doi = {10.1038/s41597-022-01533-w}, journal = {Scientific Data}, month = jul, title = {Automatic question answering for multiple stakeholders, the epidemic question answering dataset}, url = {https://doi.org/10.1038/s41597-022-01533-w}, volume = {9}, year = {2022} } -
 MultiCite: Modeling realistic citations requires moving beyond the single-sentence single-label settingAnne Lauscher, Brandon Ko, Bailey Kuehl, Sophie Johnson, Arman Cohan, David Jurgens, and Kyle LoIn NAACL, Jul 2022
MultiCite: Modeling realistic citations requires moving beyond the single-sentence single-label settingAnne Lauscher, Brandon Ko, Bailey Kuehl, Sophie Johnson, Arman Cohan, David Jurgens, and Kyle LoIn NAACL, Jul 2022Citation context analysis (CCA) is an important task in natural language processing that studies how and why scholars discuss each others’ work. Despite decades of study, computational methods for CCA have largely relied on overly-simplistic assumptions of how authors cite, which ignore several important phenomena. For instance, scholarly papers often contain rich discussions of cited work that span multiple sentences and express multiple intents concurrently. Yet, recent work in CCA is often approached as a single-sentence, single-label classification task, and thus many datasets used to develop modern computational approaches fail to capture this interesting discourse. To address this research gap, we highlight three understudied phenomena for CCA and release MULTICITE, a new dataset of 12.6K citation contexts from 1.2K computational linguistics papers that fully models these phenomena. Not only is it the largest collection of expert-annotated citation contexts to-date, MULTICITE contains multi-sentence, multi-label citation contexts annotated through-out entire full paper texts. We demonstrate how MULTICITE can enable the development of new computational methods on three important CCA tasks. We release our code and dataset at https://github.com/allenai/multicite.
@inproceedings{Lauscher2022MulticiteModelingRealistic, author = {Lauscher, Anne and Ko, Brandon and Kuehl, Bailey and Johnson, Sophie and Cohan, Arman and Jurgens, David and Lo, Kyle}, booktitle = {NAACL}, doi = {10.18653/v1/2022.naacl-main.137}, month = jul, title = {{M}ulti{C}ite: Modeling realistic citations requires moving beyond the single-sentence single-label setting}, url = {https://aclanthology.org/2022.naacl-main.137}, year = {2022} } -
 MultiVerS: Improving scientific claim verification with weak supervision and full-document contextDavid Wadden, Kyle Lo, Lucy Lu Wang, Arman Cohan, Iz Beltagy, and Hannaneh HajishirziIn Findings of NAACL, Jul 2022
MultiVerS: Improving scientific claim verification with weak supervision and full-document contextDavid Wadden, Kyle Lo, Lucy Lu Wang, Arman Cohan, Iz Beltagy, and Hannaneh HajishirziIn Findings of NAACL, Jul 2022The scientific claim verification task requires an NLP system to label scientific documents which Support or Refute an input claim, and to select evidentiary sentences (or rationales) justifying each predicted label. In this work, we present MultiVerS, which predicts a fact-checking label and identifies rationales in a multitask fashion based on a shared encoding of the claim and full document context. This approach accomplishes two key modeling goals. First, it ensures that all relevant contextual information is incorporated into each labeling decision. Second, it enables the model to learn from instances annotated with a document-level fact-checking label, but lacking sentence-level rationales. This allows MultiVerS to perform weakly-supervised domain adaptation by training on scientific documents labeled using high-precision heuristics. Our approach outperforms two competitive baselines on three scientific claim verification datasets, with particularly strong performance in zero / few-shot domain adaptation experiments. Our code and data are available at https://github.com/dwadden/multivers.
@inproceedings{Wadden2022MultiversImprovingScientific, author = {Wadden, David and Lo, Kyle and Wang, Lucy Lu and Cohan, Arman and Beltagy, Iz and Hajishirzi, Hannaneh}, booktitle = {Findings of NAACL}, doi = {10.18653/v1/2022.findings-naacl.6}, month = jul, title = {{M}ulti{V}er{S}: Improving scientific claim verification with weak supervision and full-document context}, url = {https://aclanthology.org/2022.findings-naacl.6}, year = {2022} } -
 Data Governance in the Age of Large-Scale Data-Driven Language TechnologyYacine Jernite, Huu Nguyen, Stella Biderman, Anna Rogers, Maraim Masoud, Valentin Danchev, Samson Tan, and 13 more authorsIn FAccT, Jun 2022
Data Governance in the Age of Large-Scale Data-Driven Language TechnologyYacine Jernite, Huu Nguyen, Stella Biderman, Anna Rogers, Maraim Masoud, Valentin Danchev, Samson Tan, and 13 more authorsIn FAccT, Jun 2022The recent emergence and adoption of Machine Learning technology, and specifically of Large Language Models, has drawn attention to the need for systematic and transparent management of language data. This work proposes an approach to global language data governance that attempts to organize data management amongst stakeholders, values, and rights. Our proposal is informed by prior work on distributed governance that accounts for human values and grounded by an international research collaboration that brings together researchers and practitioners from 60 countries. The framework we present is a multi-party international governance structure focused on language data, and incorporating technical and organizational tools needed to support its work.
@inproceedings{Jernite2022DataGovernanceAge, author = {Jernite, Yacine and Nguyen, Huu and Biderman, Stella and Rogers, Anna and Masoud, Maraim and Danchev, Valentin and Tan, Samson and Luccioni, Alexandra Sasha and Subramani, Nishant and Johnson, Isaac and Dupont, Gerard and Dodge, Jesse and Lo, Kyle and Talat, Zeerak and Radev, Dragomir and Gokaslan, Aaron and Nikpoor, Somaieh and Henderson, Peter and Bommasani, Rishi and Mitchell, Margaret}, booktitle = {FAccT}, doi = {10.1145/3531146.3534637}, month = jun, title = {Data Governance in the Age of Large-Scale Data-Driven Language Technology}, url = {https://doi.org/10.1145/3531146.3534637}, year = {2022} } -
 The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual DatasetHugo Laurençon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova Moral, Teven Le Scao, Leandro Von Werra, and 47 more authorsIn NeurIPS (Datasets and Benchmarks), May 2022
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual DatasetHugo Laurençon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova Moral, Teven Le Scao, Leandro Von Werra, and 47 more authorsIn NeurIPS (Datasets and Benchmarks), May 2022As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
@inproceedings{Laurencon2022BigscienceRootsCorpus, author = {Lauren{\c{c}}on, Hugo and Saulnier, Lucile and Wang, Thomas and Akiki, Christopher and del Moral, Albert Villanova and Scao, Teven Le and Werra, Leandro Von and Mou, Chenghao and Ponferrada, Eduardo Gonz{\'a}lez and Nguyen, Huu and Frohberg, J{\"o}rg and {\v{S}}a{\v{s}}ko, Mario and Lhoest, Quentin and McMillan-Major, Angelina and Dupont, G{\'e}rard and Biderman, Stella and Rogers, Anna and allal, Loubna Ben and Toni, Francesco De and Pistilli, Giada and Nguyen, Olivier and Nikpoor, Somaieh and Masoud, Maraim and Colombo, Pierre and de la Rosa, Javier and Villegas, Paulo and Thrush, Tristan and Longpre, Shayne and Nagel, Sebastian and Weber, Leon and Mu{\~n}oz, Manuel Romero and Zhu, Jian and Strien, Daniel Van and Alyafeai, Zaid and Almubarak, Khalid and Chien, Vu Minh and Gonzalez-Dios, Itziar and Soroa, Aitor and Lo, Kyle and Dey, Manan and Suarez, Pedro Ortiz and Gokaslan, Aaron and Bose, Shamik and Adelani, David Ifeoluwa and Phan, Long and Tran, Hieu and Yu, Ian and Pai, Suhas and Chim, Jenny and Lepercq, Violette and Ilic, Suzana and Mitchell, Margaret and Luccioni, Sasha and Jernite, Yacine}, booktitle = {NeurIPS (Datasets and Benchmarks)}, month = may, title = {The BigScience {ROOTS} Corpus: A 1.6{TB} Composite Multilingual Dataset}, url = {https://openreview.net/forum?id=UoEw6KigkUn}, year = {2022} } -
 ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific ConceptsSonia K. Murthy, Kyle Lo, Daniel King, Chandra Bhagavatula, Bailey Kuehl, Sophie Johnson, Jon Borchardt, and 3 more authorsIn EMNLP System Demonstrations, Dec 2022
ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific ConceptsSonia K. Murthy, Kyle Lo, Daniel King, Chandra Bhagavatula, Bailey Kuehl, Sophie Johnson, Jon Borchardt, and 3 more authorsIn EMNLP System Demonstrations, Dec 2022Systems that can automatically define unfamiliar terms hold the promise of improving the accessibility of scientific texts, especially for readers who may lack prerequisite background knowledge. However, current systems assume a single "best" description per concept, which fails to account for the many potentially useful ways a concept can be described. We present ACCoRD, an end-to-end system tackling the novel task of generating sets of descriptions of scientific concepts. Our system takes advantage of the myriad ways a concept is mentioned across the scientific literature to produce distinct, diverse descriptions of target scientific concepts in terms of different reference concepts. To support research on the task, we release an expert-annotated resource, the ACCoRD corpus, which includes 1,275 labeled contexts and 1,787 hand-authored concept descriptions. We conduct a user study demonstrating that (1) users prefer descriptions produced by our end-to-end system, and (2) users prefer multiple descriptions to a single "best" description.
@inproceedings{Murthy2022ACCoRDAM, author = {Murthy, Sonia K. and Lo, Kyle and King, Daniel and Bhagavatula, Chandra and Kuehl, Bailey and Johnson, Sophie and Borchardt, Jon and Weld, Daniel S. and Hope, Tom and Downey, Doug}, booktitle = {EMNLP System Demonstrations}, doi = {10.18653/v1/2022.emnlp-demos.20}, month = dec, title = {ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts}, url = {https://aclanthology.org/2022.emnlp-demos.20}, year = {2022} } -
 VILA: Improving Structured Content Extraction from Scientific PDFs Using Visual Layout GroupsZejiang Shen, Kyle Lo, Lucy Lu Wang, Bailey Kuehl, Daniel S. Weld, and Doug DowneyTransactions of ACL (TACL), May 2022
VILA: Improving Structured Content Extraction from Scientific PDFs Using Visual Layout GroupsZejiang Shen, Kyle Lo, Lucy Lu Wang, Bailey Kuehl, Daniel S. Weld, and Doug DowneyTransactions of ACL (TACL), May 2022Accurately extracting structured content from PDFs is a critical first step for NLP over scientific papers. Recent work has improved extraction accuracy by incorporating elementary layout information, for example, each token’s 2D position on the page, into language model pretraining. We introduce new methods that explicitly model VIsual LAyout (VILA) groups, that is, text lines or text blocks, to further improve performance. In our I-VILA approach, we show that simply inserting special tokens denoting layout group boundaries into model inputs can lead to a 1.9% Macro F1 improvement in token classification. In the H-VILA approach, we show that hierarchical encoding of layout-groups can result in up to 47% inference time reduction with less than 0.8% Macro F1 loss. Unlike prior layout-aware approaches, our methods do not require expensive additional pretraining, only fine-tuning, which we show can reduce training cost by up to 95%. Experiments are conducted on a newly curated evaluation suite, S2-VLUE, that unifies existing automatically labeled datasets and includes a new dataset of manual annotations covering diverse papers from 19 scientific disciplines. Pre-trained weights, benchmark datasets, and source code are available at https://github.com/allenai/VILA.
@article{Shen2022VilaImprovingStructured, author = {Shen, Zejiang and Lo, Kyle and Wang, Lucy Lu and Kuehl, Bailey and Weld, Daniel S. and Downey, Doug}, doi = {10.1162/tacl_a_00466}, journal = {Transactions of ACL (TACL)}, month = may, title = {{VILA}: Improving Structured Content Extraction from Scientific {PDF}s Using Visual Layout Groups}, url = {https://aclanthology.org/2022.tacl-1.22}, volume = {10}, year = {2022} } -
 Generating Scientific Claims for Zero-Shot Scientific Fact CheckingDustin Wright, David Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Isabelle Augenstein, and Lucy Lu WangIn ACL, May 2022
Generating Scientific Claims for Zero-Shot Scientific Fact CheckingDustin Wright, David Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Isabelle Augenstein, and Lucy Lu WangIn ACL, May 2022Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of training data, as annotation requires domain expertise. To address this challenge, we propose scientific claim generation, the task of generating one or more atomic and verifiable claims from scientific sentences, and demonstrate its usefulness in zero-shot fact checking for biomedical claims. We propose CLAIMGEN-BART, a new supervised method for generating claims supported by the literature, as well as KBIN, a novel method for generating claim negations. Additionally, we adapt an existing unsupervised entity-centric method of claim generation to biomedical claims, which we call CLAIMGEN-ENTITY. Experiments on zero-shot fact checking demonstrate that both CLAIMGEN-ENTITY and CLAIMGEN-BART, coupled with KBIN, achieve up to 90% performance of fully supervised models trained on manually annotated claims and evidence. A rigorous evaluation study demonstrates significant improvement in generated claim and negation quality over existing baselines
@inproceedings{Wright2022GeneratingScientificClaims, author = {Wright, Dustin and Wadden, David and Lo, Kyle and Kuehl, Bailey and Cohan, Arman and Augenstein, Isabelle and Wang, Lucy Lu}, booktitle = {ACL}, doi = {10.18653/v1/2022.acl-long.175}, month = may, title = {Generating Scientific Claims for Zero-Shot Scientific Fact Checking}, url = {https://aclanthology.org/2022.acl-long.175}, year = {2022} } -
 Exploring the Role of Local and Global Explanations in Recommender SystemsMarissa Radensky, Doug Downey, Kyle Lo, Zoran Popovic, and Daniel S WeldIn CHI (Extended Abstracts), Apr 2022
Exploring the Role of Local and Global Explanations in Recommender SystemsMarissa Radensky, Doug Downey, Kyle Lo, Zoran Popovic, and Daniel S WeldIn CHI (Extended Abstracts), Apr 2022Explanations are well-known to improve recommender systems’ transparency. These explanations may be local, explaining individual recommendations, or global, explaining the recommender model overall. Despite their widespread use, there has been little investigation into the relative benefits of the two explanation approaches. We conducted a 30-participant exploratory study and a 30-participant controlled user study with a research-paper recommender to analyze how providing local, global, or both explanations influences user understanding of system behavior. Our results provide evidence suggesting that both are more helpful than either alone for explaining how to improve recommendations, yet both appeared less helpful than global alone for efficiently identifying false positive and negative recommendations. However, we note that the two explanation approaches may be better compared in a higher-stakes or more opaque domain.
@inproceedings{Radensky2022ExploringRoleLocal, author = {Radensky, Marissa and Downey, Doug and Lo, Kyle and Popovic, Zoran and Weld, Daniel S}, booktitle = {CHI (Extended Abstracts)}, doi = {10.1145/3491101.3519795}, month = apr, title = {Exploring the Role of Local and Global Explanations in Recommender Systems}, url = {https://doi.org/10.1145/3491101.3519795}, year = {2022} } -
 Infrastructure for rapid open knowledge network developmentMichael Cafarella, Michael Anderson, Iz Beltagy, Arie Cattan, Sarah Chasins, Ido Dagan, Doug Downey, and 19 more authorsAI Magazine, Mar 2022
Infrastructure for rapid open knowledge network developmentMichael Cafarella, Michael Anderson, Iz Beltagy, Arie Cattan, Sarah Chasins, Ido Dagan, Doug Downey, and 19 more authorsAI Magazine, Mar 2022Abstract The past decade has witnessed a growth in the use of knowledge graph technologies for advanced data search, data integration, and query-answering applications. The leading example of a public, general-purpose open knowledge network (aka knowledge graph) is Wikidata, which has demonstrated remarkable advances in quality and coverage over this time. Proprietary knowledge graphs drive some of the leading applications of the day including, for example, Google Search, Alexa, Siri, and Cortana. Open Knowledge Networks are exciting: they promise the power of structured database-like queries with the potential for the wide coverage that is today only provided by the Web. With the current state of the art, building, using, and scaling large knowledge networks can still be frustratingly slow. This article describes a National Science Foundation Convergence Accelerator project to build a set of Knowledge Network Programming Infrastructure systems to address this issue.
@article{Cafarella2022InfrastructureRapidOpen, aaai = {aimagazine/article/view/19126}, author = {Cafarella, Michael and Anderson, Michael and Beltagy, Iz and Cattan, Arie and Chasins, Sarah and Dagan, Ido and Downey, Doug and Etzioni, Oren and Feldman, Sergey and Gao, Tian and Hope, Tom and Huang, Kexin and Johnson, Sophie and King, Daniel and Lo, Kyle and Lou, Yuze and Shapiro, Matthew and Shen, Dinghao and Subramanian, Shivashankar and Wang, Lucy Lu and Wang, Yuning and Wang, Yitong and Weld, Daniel S. and Vo-Phamhi, Jenny and Zeng, Anna and Zou, Jiayun}, doi = {https://doi.org/10.1002/aaai.12038}, journal = {AI Magazine}, month = mar, title = {Infrastructure for rapid open knowledge network development}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/aaai.12038}, volume = {43}, year = {2022} }














2021
-
 FLEX: Unifying Evaluation for Few-Shot NLPJonathan Bragg, Arman Cohan, Kyle Lo, and Iz BeltagyIn NeurIPS, Dec 2021
FLEX: Unifying Evaluation for Few-Shot NLPJonathan Bragg, Arman Cohan, Kyle Lo, and Iz BeltagyIn NeurIPS, Dec 2021Few-shot NLP research is highly active, yet conducted in disjoint research threads with evaluation suites that lack challenging-yet-realistic testing setups and fail to employ careful experimental design. Consequently, the community does not know which techniques perform best or even if they outperform simple baselines. In response, we formulate the FLEX Principles, a set of requirements and best practices for unified, rigorous, valid, and cost-sensitive few-shot NLP evaluation. These principles include Sample Size Design, a novel approach to benchmark design that optimizes statistical accuracy and precision while keeping evaluation costs manageable. Following the principles, we release the FLEX benchmark, which includes four few-shot transfer settings, zero-shot evaluation, and a public leaderboard that covers diverse NLP tasks. In addition, we present UniFew, a prompt-based model for few-shot learning that unifies pretraining and finetuning prompt formats, eschewing complex machinery of recent prompt-based approaches in adapting downstream task formats to language model pretraining objectives. We demonstrate that despite simplicity, UniFew achieves results competitive with both popular meta-learning and prompt-based approaches.
@inproceedings{Bragg2021FlexUnifyingEvaluation, author = {Bragg, Jonathan and Cohan, Arman and Lo, Kyle and Beltagy, Iz}, booktitle = {NeurIPS}, month = dec, title = {FLEX: Unifying Evaluation for Few-Shot NLP}, url = {https://proceedings.neurips.cc/paper/2021/file/8493eeaccb772c0878f99d60a0bd2bb3-Paper.pdf}, volume = {34}, year = {2021} } -
 Explaining Relationships Between Scientific DocumentsKelvin Luu, Xinyi Wu, Rik Koncel-Kedziorski, Kyle Lo, Isabel Cachola, and Noah A. SmithIn ACL, Aug 2021
Explaining Relationships Between Scientific DocumentsKelvin Luu, Xinyi Wu, Rik Koncel-Kedziorski, Kyle Lo, Isabel Cachola, and Noah A. SmithIn ACL, Aug 2021We address the task of explaining relationships between two scientific documents using natural language text. This task requires modeling the complex content of long technical documents, deducing a relationship between these documents, and expressing the details of that relationship in text. In addition to the theoretical interest of this task, successful solutions can help improve researcher efficiency in search and review. In this paper we establish a dataset of 622K examples from 154K documents. We pretrain a large language model to serve as the foundation for autoregressive approaches to the task. We explore the impact of taking different views on the two documents, including the use of dense representations extracted with scientific IE systems. We provide extensive automatic and human evaluations which show the promise of such models, but make clear challenges for future work.
@inproceedings{Luu2021ExplainingRelationshipsBetween, author = {Luu, Kelvin and Wu, Xinyi and Koncel-Kedziorski, Rik and Lo, Kyle and Cachola, Isabel and Smith, Noah A.}, booktitle = {ACL}, doi = {10.18653/v1/2021.acl-long.166}, month = aug, title = {Explaining Relationships Between Scientific Documents}, url = {https://aclanthology.org/2021.acl-long.166}, year = {2021} } -
 Overview of the Second Workshop on Scholarly Document ProcessingIz Beltagy, Arman Cohan, Guy Feigenblat, Dayne Freitag, Tirthankar Ghosal, Keith Hall, Drahomira Herrmannova, and 8 more authorsIn Scholarly Document Processing (SDP) Workshop, Jun 2021
Overview of the Second Workshop on Scholarly Document ProcessingIz Beltagy, Arman Cohan, Guy Feigenblat, Dayne Freitag, Tirthankar Ghosal, Keith Hall, Drahomira Herrmannova, and 8 more authorsIn Scholarly Document Processing (SDP) Workshop, Jun 2021With the ever-increasing pace of research and high volume of scholarly communication, scholars face a daunting task. Not only must they keep up with the growing literature in their own and related fields, scholars increasingly also need to rebut pseudo-science and disinformation. These needs have motivated an increasing focus on computational methods for enhancing search, summarization, and analysis of scholarly documents. However, the various strands of research on scholarly document processing remain fragmented. To reach out to the broader NLP and AI/ML community, pool distributed efforts in this area, and enable shared access to published research, we held the 2nd Workshop on Scholarly Document Processing (SDP) at NAACL 2021 as a virtual event (https://sdproc.org/2021/). The SDP workshop consisted of a research track, three invited talks, and three Shared Tasks (LongSumm 2021, SCIVER, and 3C). The program was geared towards the application of NLP, information retrieval, and data mining for scholarly documents, with an emphasis on identifying and providing solutions to open challenges.
@inproceedings{Beltagy2021OverviewSecondWorkshop, author = {Beltagy, Iz and Cohan, Arman and Feigenblat, Guy and Freitag, Dayne and Ghosal, Tirthankar and Hall, Keith and Herrmannova, Drahomira and Knoth, Petr and Lo, Kyle and Mayr, Philipp and Patton, Robert and Shmueli-Scheuer, Michal and de Waard, Anita and Wang, Kuansan and Wang, Lucy Lu}, booktitle = {Scholarly Document Processing (SDP) Workshop}, doi = {10.18653/v1/2021.sdp-1.22}, month = jun, title = {Overview of the Second Workshop on Scholarly Document Processing}, url = {https://aclanthology.org/2021.sdp-1.22}, year = {2021} } -
 A Dataset of Information-Seeking Questions and Answers Anchored in Research PapersPradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt GardnerIn NAACL, Jun 2021
A Dataset of Information-Seeking Questions and Answers Anchored in Research PapersPradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt GardnerIn NAACL, Jun 2021Readers of academic research papers often read with the goal of answering specific questions. Question Answering systems that can answer those questions can make consumption of the content much more efficient. However, building such tools requires data that reflect the difficulty of the task arising from complex reasoning about claims made in multiple parts of a paper. In contrast, existing information-seeking question answering datasets usually contain questions about generic factoid-type information. We therefore present Qasper, a dataset of 5049 questions over 1585 Natural Language Processing papers. Each question is written by an NLP practitioner who read only the title and abstract of the corresponding paper, and the question seeks information present in the full text. The questions are then answered by a separate set of NLP practitioners who also provide supporting evidence to answers. We find that existing models that do well on other QA tasks do not perform well on answering these questions, underperforming humans by at least 27 F1 points when answering them from entire papers, motivating further research in document-grounded, information-seeking QA, which our dataset is designed to facilitate.
@inproceedings{Dasigi2021DatasetInformationSeeking, author = {Dasigi, Pradeep and Lo, Kyle and Beltagy, Iz and Cohan, Arman and Smith, Noah A. and Gardner, Matt}, booktitle = {NAACL}, doi = {10.18653/v1/2021.naacl-main.365}, month = jun, title = {A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers}, url = {https://aclanthology.org/2021.naacl-main.365}, year = {2021} } -
 Overview and Insights from the SCIVER shared task on Scientific Claim VerificationDavid Wadden, and Kyle LoIn Scholarly Document Processing (SDP) Workshop, Jun 2021
Overview and Insights from the SCIVER shared task on Scientific Claim VerificationDavid Wadden, and Kyle LoIn Scholarly Document Processing (SDP) Workshop, Jun 2021We present an overview of the SCIVER shared task, presented at the 2nd Scholarly Document Processing (SDP) workshop at NAACL 2021. In this shared task, systems were provided a scientific claim and a corpus of research abstracts, and asked to identify which articles Support or Refute the claim as well as provide evidentiary sentences justifying those labels. 11 teams made a total of 14 submissions to the shared task leaderboard, leading to an improvement of more than +23 F1 on the primary task evaluation metric. In addition to surveying the participating systems, we provide several insights into modeling approaches to support continued progress and future research on the important and challenging task of scientific claim verification.
@inproceedings{Wadden2021OverviewInsightsSciver, author = {Wadden, David and Lo, Kyle}, booktitle = {Scholarly Document Processing (SDP) Workshop}, doi = {10.18653/v1/2021.sdp-1.16}, month = jun, title = {Overview and Insights from the {SCIVER} shared task on Scientific Claim Verification}, url = {https://aclanthology.org/2021.sdp-1.16}, year = {2021} } -
 Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and SymbolsAndrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S. Weld, and Marti A. HearstIn CHI, May 2021
Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and SymbolsAndrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S. Weld, and Marti A. HearstIn CHI, May 2021Despite the central importance of research papers to scientific progress, they can be difficult to read. Comprehension is often stymied when the information needed to understand a passage resides somewhere else—in another section, or in another paper. In this work, we envision how interfaces can bring definitions of technical terms and symbols to readers when and where they need them most. We introduce ScholarPhi, an augmented reading interface with four novel features: (1) tooltips that surface position-sensitive definitions from elsewhere in a paper, (2) a filter over the paper that “declutters” it to reveal how the term or symbol is used across the paper, (3) automatic equation diagrams that expose multiple definitions in parallel, and (4) an automatically generated glossary of important terms and symbols. A usability study showed that the tool helps researchers of all experience levels read papers. Furthermore, researchers were eager to have ScholarPhi’s definitions available to support their everyday reading.
@inproceedings{Head2021AugmentingScientificPapers, author = {Head, Andrew and Lo, Kyle and Kang, Dongyeop and Fok, Raymond and Skjonsberg, Sam and Weld, Daniel S. and Hearst, Marti A.}, booktitle = {CHI}, doi = {10.1145/3411764.3445648}, month = may, title = {Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and Symbols}, url = {https://doi.org/10.1145/3411764.3445648}, year = {2021} } -
 Discourse Understanding and Factual Consistency in Abstractive SummarizationSaadia Gabriel, Antoine Bosselut, Jeff Da, Ari Holtzman, Jan Buys, Kyle Lo, Asli Celikyilmaz, and 1 more authorIn EACL, Apr 2021
Discourse Understanding and Factual Consistency in Abstractive SummarizationSaadia Gabriel, Antoine Bosselut, Jeff Da, Ari Holtzman, Jan Buys, Kyle Lo, Asli Celikyilmaz, and 1 more authorIn EACL, Apr 2021We introduce a general framework for abstractive summarization with factual consistency and distinct modeling of the narrative flow in an output summary. Our work addresses current limitations of models for abstractive summarization that often hallucinate information or generate summaries with coherence issues. To generate abstractive summaries with factual consistency and narrative flow, we propose Cooperative Generator-Discriminator Networks (Co-opNet), a novel transformer-based framework where the generator works with a discriminator architecture to compose coherent long-form summaries. We explore four different discriminator objectives which each capture a different aspect of coherence, including whether salient spans of generated abstracts are hallucinated or appear in the input context, and the likelihood of sentence adjacency in generated abstracts. We measure the ability of Co-opNet to learn these objectives with arXiv scientific papers, using the abstracts as a proxy for gold long-form scientific article summaries. Empirical results from automatic and human evaluations demonstrate that Co-opNet learns to summarize with considerably improved global coherence compared to competitive baselines.
@inproceedings{Gabriel2021DiscourseUnderstandingFactual, author = {Gabriel, Saadia and Bosselut, Antoine and Da, Jeff and Holtzman, Ari and Buys, Jan and Lo, Kyle and Celikyilmaz, Asli and Choi, Yejin}, booktitle = {EACL}, doi = {10.18653/v1/2021.eacl-main.34}, month = apr, title = {Discourse Understanding and Factual Consistency in Abstractive Summarization}, url = {https://aclanthology.org/2021.eacl-main.34}, year = {2021} } -
 Searching for scientific evidence in a pandemic: An overview of TREC-COVIDKirk Roberts, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, Kyle Lo, Ian Soboroff, Ellen Voorhees, and 2 more authorsJournal of Biomedical Informatics, Apr 2021
Searching for scientific evidence in a pandemic: An overview of TREC-COVIDKirk Roberts, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, Kyle Lo, Ian Soboroff, Ellen Voorhees, and 2 more authorsJournal of Biomedical Informatics, Apr 2021We present an overview of the TREC-COVID Challenge, an information retrieval (IR) shared task to evaluate search on scientific literature related to COVID-19. The goals of TREC-COVID include the construction of a pandemic search test collection and the evaluation of IR methods for COVID-19. The challenge was conducted over five rounds from April to July 2020, with participation from 92 unique teams and 556 individual submissions. A total of 50 topics (sets of related queries) were used in the evaluation, starting at 30 topics for Round 1 and adding 5 new topics per round to target emerging topics at that state of the still-emerging pandemic. This paper provides a comprehensive overview of the structure and results of TREC-COVID. Specifically, the paper provides details on the background, task structure, topic structure, corpus, participation, pooling, assessment, judgments, results, top-performing systems, lessons learned, and benchmark datasets.
@article{Roberts2021SearchingScientificEvidence, author = {Roberts, Kirk and Alam, Tasmeer and Bedrick, Steven and Demner-Fushman, Dina and Lo, Kyle and Soboroff, Ian and Voorhees, Ellen and Wang, Lucy Lu and Hersh, William R.}, doi = {https://doi.org/10.1016/j.jbi.2021.103865}, journal = {Journal of Biomedical Informatics}, month = apr, title = {Searching for scientific evidence in a pandemic: An overview of TREC-COVID}, url = {https://www.sciencedirect.com/science/article/pii/S1532046421001945}, volume = {121}, year = {2021} } -
 TREC-COVID: Constructing a Pandemic Information Retrieval Test CollectionEllen Voorhees, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, William R. Hersh, Kyle Lo, Kirk Roberts, and 2 more authorsSIGIR Forum, Feb 2021
TREC-COVID: Constructing a Pandemic Information Retrieval Test CollectionEllen Voorhees, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, William R. Hersh, Kyle Lo, Kirk Roberts, and 2 more authorsSIGIR Forum, Feb 2021TREC-COVID is a community evaluation designed to build a test collection that captures the information needs of biomedical researchers using the scientific literature during a pandemic. One of the key characteristics of pandemic search is the accelerated rate of change: the topics of interest evolve as the pandemic progresses and the scientific literature in the area explodes. The COVID-19 pandemic provides an opportunity to capture this progression as it happens. TREC-COVID, in creating a test collection around COVID-19 literature, is building infrastructure to support new research and technologies in pandemic search.
@article{Voorhees2021TrecCovidConstructing, author = {Voorhees, Ellen and Alam, Tasmeer and Bedrick, Steven and Demner-Fushman, Dina and Hersh, William R. and Lo, Kyle and Roberts, Kirk and Soboroff, Ian and Wang, Lucy Lu}, doi = {10.1145/3451964.3451965}, journal = {SIGIR Forum}, month = feb, title = {TREC-COVID: Constructing a Pandemic Information Retrieval Test Collection}, url = {https://doi.org/10.1145/3451964.3451965}, volume = {54}, year = {2021} } -
 Harnessing the power of smart and connected health to tackle COVID-19: IoT, AI, robotics, and blockchain for a better worldFarshad Firouzi, Bahar Farahani, Mahmoud Daneshmand, Kathy Grise, Jaeseung Song, Roberto Saracco, Lucy Lu Wang, and 24 more authorsIEEE Internet of Things Journal, Feb 2021
Harnessing the power of smart and connected health to tackle COVID-19: IoT, AI, robotics, and blockchain for a better worldFarshad Firouzi, Bahar Farahani, Mahmoud Daneshmand, Kathy Grise, Jaeseung Song, Roberto Saracco, Lucy Lu Wang, and 24 more authorsIEEE Internet of Things Journal, Feb 2021As COVID-19 hounds the world, the common cause of finding a swift solution to manage the pandemic has brought together researchers, institutions, governments, and society at large. The Internet of Things (IoT), artificial intelligence (AI)–including machine learning (ML) and Big Data analytics–as well as Robotics and Blockchain, are the four decisive areas of technological innovation that have been ingenuity harnessed to fight this pandemic and future ones. While these highly interrelated smart and connected health technologies cannot resolve the pandemic overnight and may not be the only answer to the crisis, they can provide greater insight into the disease and support frontline efforts to prevent and control the pandemic. This article provides a blend of discussions on the contribution of these digital technologies, propose several complementary and multidisciplinary techniques to combat COVID-19, offer opportunities for more holistic studies, and accelerate knowledge acquisition and scientific discoveries in pandemic research. First, four areas, where IoT can contribute are discussed, namely: 1) tracking and tracing; 2) remote patient monitoring (RPM) by wearable IoT (WIoT); 3) personal digital twins (PDTs); and 4) real-life use case: ICT/IoT solution in South Korea. Second, the role and novel applications of AI are explained, namely: 1) diagnosis and prognosis; 2) risk prediction; 3) vaccine and drug development; 4) research data set; 5) early warnings and alerts; 6) social control and fake news detection; and 7) communication and chatbot. Third, the main uses of robotics and drone technology are analyzed, including: 1) crowd surveillance; 2) public announcements; 3) screening and diagnosis; and 4) essential supply delivery. Finally, we discuss how distributed ledger technologies (DLTs), of which blockchain is a common example, can be combined with other technologies for tackling COVID-19.
@article{Firouzi2021HarnessingPower, author = {Firouzi, Farshad and Farahani, Bahar and Daneshmand, Mahmoud and Grise, Kathy and Song, Jaeseung and Saracco, Roberto and Wang, Lucy Lu and Lo, Kyle and Angelov, Plamen and Soares, Eduardo and Loh, Po-Shen and Talebpour, Zeynab and Moradi, Reza and Goodarzi, Mohsen and Ashraf, Haleh and Talebpour, Mohammad and Talebpour, Alireza and Romeo, Luca and Das, Rupam and Heidari, Hadi and Pasquale, Dana and Moody, James and Woods, Chris and Huang, Erich S and Barnaghi, Payam and Sarrafzadeh, Majid and Li, Ron and Beck, Kristen L and Isayev, Olexandr and Sung, Nakmyoung and Luo, Alan}, doi = {10.1109/JIOT.2021.3073904}, journal = {IEEE Internet of Things Journal}, needs_review = {true}, title = {Harnessing the power of smart and connected health to tackle COVID-19: IoT, AI, robotics, and blockchain for a better world}, url = {https://ieeexplore.ieee.org/abstract/document/9406879/}, volume = {8}, year = {2021} }










2020
-
 Text mining approaches for dealing with the rapidly expanding literature on COVID-19Lucy Lu Wang, and Kyle LoBriefings in Bioinformatics, Dec 2020
Text mining approaches for dealing with the rapidly expanding literature on COVID-19Lucy Lu Wang, and Kyle LoBriefings in Bioinformatics, Dec 2020More than 50 000 papers have been published about COVID-19 since the beginning of 2020 and several hundred new papers continue to be published every day. This incredible rate of scientific productivity leads to information overload, making it difficult for researchers, clinicians and public health officials to keep up with the latest findings. Automated text mining techniques for searching, reading and summarizing papers are helpful for addressing information overload. In this review, we describe the many resources that have been introduced to support text mining applications over the COVID-19 literature; specifically, we discuss the corpora, modeling resources, systems and shared tasks that have been introduced for COVID-19. We compile a list of 39 systems that provide functionality such as search, discovery, visualization and summarization over the COVID-19 literature. For each system, we provide a qualitative description and assessment of the system’s performance, unique data or user interface features and modeling decisions. Many systems focus on search and discovery, though several systems provide novel features, such as the ability to summarize findings over multiple documents or linking between scientific articles and clinical trials. We also describe the public corpora, models and shared tasks that have been introduced to help reduce repeated effort among community members; some of these resources (especially shared tasks) can provide a basis for comparing the performance of different systems. Finally, we summarize promising results and open challenges for text mining the COVID-19 literature.
@article{Wang2020TextMiningApproaches, author = {Wang, Lucy Lu and Lo, Kyle}, doi = {10.1093/bib/bbaa296}, journal = {Briefings in Bioinformatics}, month = dec, title = {{Text mining approaches for dealing with the rapidly expanding literature on COVID-19}}, url = {https://doi.org/10.1093/bib/bbaa296}, volume = {22}, year = {2020} } -
 Mitigating Biases in CORD-19 for Analyzing COVID-19 LiteratureAnshul Kanakia, Kuansan Wang, Yuxiao Dong, Boya Xie, Kyle Lo, Zhihong Shen, Lucy Lu Wang, and 4 more authorsFrontiers in Research Metrics and Analytics, Nov 2020
Mitigating Biases in CORD-19 for Analyzing COVID-19 LiteratureAnshul Kanakia, Kuansan Wang, Yuxiao Dong, Boya Xie, Kyle Lo, Zhihong Shen, Lucy Lu Wang, and 4 more authorsFrontiers in Research Metrics and Analytics, Nov 2020On the behest of the Office of Science and Technology Policy in the White House, six institutions, including ours, have created an open research dataset called COVID-19 Research Dataset (CORD-19) to facilitate the development of question-answering systems that can assist researchers in finding relevant research on COVID-19. As of May 27, 2020, CORD-19 includes more than 100,000 open access publications from major publishers and PubMed as well as preprint articles deposited into medRxiv, bioRxiv, and arXiv. Recent years, however, have also seen question-answering and other machine learning systems exhibit harmful behaviors to humans due to biases in the training data. It is imperative and only ethical for modern scientists to be vigilant in inspecting and be prepared to mitigate the potential biases when working with any datasets. This article describes a framework to examine biases in scientific document collections like CORD-19 by comparing their properties with those derived from the citation behaviors of the entire scientific community. In total, three expanded sets are created for the analyses: 1) the enclosure set CORD-19E composed of CORD-19 articles and their references and citations, mirroring the methodology used in the renowned “A Century of Physics” analysis; 2) the full closure graph CORD-19C that recursively includes references starting with CORD-19; and 3) the inflection closure CORD-19I, that is, a much smaller subset of CORD-19C but already appropriate for statistical analysis based on the theory of the scale-free nature of the citation network. Taken together, all these expanded datasets show much smoother trends when used to analyze global COVID-19 research. The results suggest that while CORD-19 exhibits a strong tilt toward recent and topically focused articles, the knowledge being explored to attack the pandemic encompasses a much longer time span and is very interdisciplinary. A question-answering system with such expanded scope of knowledge may perform better in understanding the literature and answering related questions. However, while CORD-19 appears to have topical coverage biases compared to the expanded sets, the collaboration patterns, especially in terms of team sizes and geographical distributions, are captured very well already in CORD-19 as the raw statistics and trends agree with those from larger datasets.
@article{Kanakia2020MitigatingBiasesCord, author = {Kanakia, Anshul and Wang, Kuansan and Dong, Yuxiao and Xie, Boya and Lo, Kyle and Shen, Zhihong and Wang, Lucy Lu and Huang, Chiyuan and Eide, Darrin and Kohlmeier, Sebastian and Wu, Chieh-Han}, doi = {10.3389/frma.2020.596624}, journal = {Frontiers in Research Metrics and Analytics}, month = nov, title = {Mitigating Biases in CORD-19 for Analyzing COVID-19 Literature}, url = {https://www.frontiersin.org/articles/10.3389/frma.2020.596624}, volume = {5}, year = {2020} } -
 TLDR: Extreme Summarization of Scientific DocumentsIsabel Cachola, Kyle Lo, Arman Cohan, and Daniel WeldIn Findings of EMNLP, Nov 2020
TLDR: Extreme Summarization of Scientific DocumentsIsabel Cachola, Kyle Lo, Arman Cohan, and Daniel WeldIn Findings of EMNLP, Nov 2020We introduce TLDR generation, a new form of extreme summarization, for scientific papers. TLDR generation involves high source compression and requires expert background knowledge and understanding of complex domain-specific language. To facilitate study on this task, we introduce SCITLDR, a new multi-target dataset of 5.4K TLDRs over 3.2K papers. SCITLDR contains both author-written and expert-derived TLDRs, where the latter are collected using a novel annotation protocol that produces high-quality summaries while minimizing annotation burden. We propose CATTS, a simple yet effective learning strategy for generating TLDRs that exploits titles as an auxiliary training signal. CATTS improves upon strong baselines under both automated metrics and human evaluations. Data and code are publicly available at https://github.com/allenai/scitldr.
@inproceedings{Cachola2020TldrExtremeSummarization, author = {Cachola, Isabel and Lo, Kyle and Cohan, Arman and Weld, Daniel}, booktitle = {Findings of EMNLP}, doi = {10.18653/v1/2020.findings-emnlp.428}, month = nov, title = {{TLDR}: Extreme Summarization of Scientific Documents}, url = {https://aclanthology.org/2020.findings-emnlp.428}, year = {2020} } -
 Document-Level Definition Detection in Scholarly Documents: Existing Models, Error Analyses, and Future DirectionsDongyeop Kang, Andrew Head, Risham Sidhu, Kyle Lo, Daniel Weld, and Marti A. HearstIn Scholarly Document Processing (SDP) Workshop, Nov 2020
Document-Level Definition Detection in Scholarly Documents: Existing Models, Error Analyses, and Future DirectionsDongyeop Kang, Andrew Head, Risham Sidhu, Kyle Lo, Daniel Weld, and Marti A. HearstIn Scholarly Document Processing (SDP) Workshop, Nov 2020The task of definition detection is important for scholarly papers, because papers often make use of technical terminology that may be unfamiliar to readers. Despite prior work on definition detection, current approaches are far from being accurate enough to use in realworld applications. In this paper, we first perform in-depth error analysis of the current best performing definition detection system and discover major causes of errors. Based on this analysis, we develop a new definition detection system, HEDDEx, that utilizes syntactic features, transformer encoders, and heuristic filters, and evaluate it on a standard sentence-level benchmark. Because current benchmarks evaluate randomly sampled sentences, we propose an alternative evaluation that assesses every sentence within a document. This allows for evaluating recall in addition to precision. HEDDEx outperforms the leading system on both the sentence-level and the document-level tasks, by 12.7 F1 points and 14.4 F1 points, respectively. We note that performance on the high-recall document-level task is much lower than in the standard evaluation approach, due to the necessity of incorporation of document structure as features. We discuss remaining challenges in document-level definition detection, ideas for improvements, and potential issues for the development of reading aid applications.
@inproceedings{Kang2020DocumentLevelDefinition, author = {Kang, Dongyeop and Head, Andrew and Sidhu, Risham and Lo, Kyle and Weld, Daniel and Hearst, Marti A.}, booktitle = {Scholarly Document Processing (SDP) Workshop}, doi = {10.18653/v1/2020.sdp-1.22}, month = nov, title = {Document-Level Definition Detection in Scholarly Documents: Existing Models, Error Analyses, and Future Directions}, url = {https://aclanthology.org/2020.sdp-1.22}, year = {2020} } -
 Fact or Fiction: Verifying Scientific ClaimsDavid Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine Zuylen, Arman Cohan, and Hannaneh HajishirziIn EMNLP, Nov 2020
Fact or Fiction: Verifying Scientific ClaimsDavid Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine Zuylen, Arman Cohan, and Hannaneh HajishirziIn EMNLP, Nov 2020We introduce scientific claim verification, a new task to select abstracts from the research literature containing evidence that SUPPORTS or REFUTES a given scientific claim, and to identify rationales justifying each decision. To study this task, we construct SciFact, a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts annotated with labels and rationales. We develop baseline models for SciFact, and demonstrate that simple domain adaptation techniques substantially improve performance compared to models trained on Wikipedia or political news. We show that our system is able to verify claims related to COVID-19 by identifying evidence from the CORD-19 corpus. Our experiments indicate that SciFact will provide a challenging testbed for the development of new systems designed to retrieve and reason over corpora containing specialized domain knowledge. Data and code for this new task are publicly available at https://github.com/allenai/scifact. A leaderboard and COVID-19 fact-checking demo are available at https://scifact.apps.allenai.org.
@inproceedings{Wadden2020FactFictionVerifying, author = {Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh}, booktitle = {EMNLP}, doi = {10.18653/v1/2020.emnlp-main.609}, month = nov, title = {Fact or Fiction: Verifying Scientific Claims}, url = {https://aclanthology.org/2020.emnlp-main.609}, year = {2020} } -
 TREC-COVID: rationale and structure of an information retrieval shared task for COVID-19Kirk Roberts, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, Kyle Lo, Ian Soboroff, Ellen Voorhees, and 2 more authorsJournal of the American Medical Informatics Association, Jul 2020
TREC-COVID: rationale and structure of an information retrieval shared task for COVID-19Kirk Roberts, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, Kyle Lo, Ian Soboroff, Ellen Voorhees, and 2 more authorsJournal of the American Medical Informatics Association, Jul 2020TREC-COVID is an information retrieval (IR) shared task initiated to support clinicians and clinical research during the COVID-19 pandemic. IR for pandemics breaks many normal assumptions, which can be seen by examining 9 important basic IR research questions related to pandemic situations. TREC-COVID differs from traditional IR shared task evaluations with special considerations for the expected users, IR modality considerations, topic development, participant requirements, assessment process, relevance criteria, evaluation metrics, iteration process, projected timeline, and the implications of data use as a post-task test collection. This article describes how all these were addressed for the particular requirements of developing IR systems under a pandemic situation. Finally, initial participation numbers are also provided, which demonstrate the tremendous interest the IR community has in this effort.
@article{Roberts2020TrecCovidRationale, author = {Roberts, Kirk and Alam, Tasmeer and Bedrick, Steven and Demner-Fushman, Dina and Lo, Kyle and Soboroff, Ian and Voorhees, Ellen and Wang, Lucy Lu and Hersh, William R}, doi = {10.1093/jamia/ocaa091}, journal = {Journal of the American Medical Informatics Association}, month = jul, title = {{TREC-COVID: rationale and structure of an information retrieval shared task for COVID-19}}, url = {https://doi.org/10.1093/jamia/ocaa091}, volume = {27}, year = {2020} } -
 Don’t Stop Pretraining: Adapt Language Models to Domains and TasksSuchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. SmithIn ACL, Jul 2020
Don’t Stop Pretraining: Adapt Language Models to Domains and TasksSuchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. SmithIn ACL, Jul 2020Honorable Mention for Best Paper
Language models pretrained on text from a wide variety of sources form the foundation of today’s NLP. In light of the success of these broad-coverage models, we investigate whether it is still helpful to tailor a pretrained model to the domain of a target task. We present a study across four domains (biomedical and computer science publications, news, and reviews) and eight classification tasks, showing that a second phase of pretraining in-domain (domain-adaptive pretraining) leads to performance gains, under both high- and low-resource settings. Moreover, adapting to the task’s unlabeled data (task-adaptive pretraining) improves performance even after domain-adaptive pretraining. Finally, we show that adapting to a task corpus augmented using simple data selection strategies is an effective alternative, especially when resources for domain-adaptive pretraining might be unavailable. Overall, we consistently find that multi-phase adaptive pretraining offers large gains in task performance.
@inproceedings{Gururangan2020DontStopPretraining, author = {Gururangan, Suchin and Marasovi{\'c}, Ana and Swayamdipta, Swabha and Lo, Kyle and Beltagy, Iz and Downey, Doug and Smith, Noah A.}, booktitle = {ACL}, doi = {10.18653/v1/2020.acl-main.740}, month = jul, title = {Don{'}t Stop Pretraining: Adapt Language Models to Domains and Tasks}, url = {https://aclanthology.org/2020.acl-main.740}, year = {2020} } -
 S2ORC: The Semantic Scholar Open Research CorpusKyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel WeldIn ACL, Jul 2020
S2ORC: The Semantic Scholar Open Research CorpusKyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel WeldIn ACL, Jul 2020We introduce S2ORC, a large corpus of 81.1M English-language academic papers spanning many academic disciplines. The corpus consists of rich metadata, paper abstracts, resolved bibliographic references, as well as structured full text for 8.1M open access papers. Full text is annotated with automatically-detected inline mentions of citations, figures, and tables, each linked to their corresponding paper objects. In S2ORC, we aggregate papers from hundreds of academic publishers and digital archives into a unified source, and create the largest publicly-available collection of machine-readable academic text to date. We hope this resource will facilitate research and development of tools and tasks for text mining over academic text.
@inproceedings{Lo2020S2orcSemanticScholar, author = {Lo, Kyle and Wang, Lucy Lu and Neumann, Mark and Kinney, Rodney and Weld, Daniel}, booktitle = {ACL}, doi = {10.18653/v1/2020.acl-main.447}, month = jul, title = {{S}2{ORC}: The Semantic Scholar Open Research Corpus}, url = {https://aclanthology.org/2020.acl-main.447}, year = {2020} } -
 CORD-19: The COVID-19 Open Research DatasetLucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, Russell Reas, Jiangjiang Yang, Doug Burdick, Darrin Eide, and 21 more authorsIn NLP for COVID-19 Workshop, Jul 2020
CORD-19: The COVID-19 Open Research DatasetLucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, Russell Reas, Jiangjiang Yang, Doug Burdick, Darrin Eide, and 21 more authorsIn NLP for COVID-19 Workshop, Jul 2020The COVID-19 Open Research Dataset (CORD-19) is a growing resource of scientific papers on COVID-19 and related historical coronavirus research. CORD-19 is designed to facilitate the development of text mining and information retrieval systems over its rich collection of metadata and structured full text papers. Since its release, CORD-19 has been downloaded over 200K times and has served as the basis of many COVID-19 text mining and discovery systems. In this article, we describe the mechanics of dataset construction, highlighting challenges and key design decisions, provide an overview of how CORD-19 has been used, and describe several shared tasks built around the dataset. We hope this resource will continue to bring together the computing community, biomedical experts, and policy makers in the search for effective treatments and management policies for COVID-19.
@inproceedings{Wang2020Cord19Covid, author = {Wang, Lucy Lu and Lo, Kyle and Chandrasekhar, Yoganand and Reas, Russell and Yang, Jiangjiang and Burdick, Doug and Eide, Darrin and Funk, Kathryn and Katsis, Yannis and Kinney, Rodney Michael and Li, Yunyao and Liu, Ziyang and Merrill, William and Mooney, Paul and Murdick, Dewey A. and Rishi, Devvret and Sheehan, Jerry and Shen, Zhihong and Stilson, Brandon and Wade, Alex D. and Wang, Kuansan and Wang, Nancy Xin Ru and Wilhelm, Christopher and Xie, Boya and Raymond, Douglas M. and Weld, Daniel S. and Etzioni, Oren and Kohlmeier, Sebastian}, booktitle = {NLP for COVID-19 Workshop}, month = jul, title = {{CORD-19}: The {COVID-19} Open Research Dataset}, url = {https://aclanthology.org/2020.nlpcovid19-acl.1}, year = {2020} } -
 Overview of the 2020 epidemic question answering trackTravis R Goodwin, Dina Demner-Fushman, Kyle Lo, Lucy Lu Wang, William R Hersh, HT Dang, and Ian M SoboroffIn Text Analysis Conference, Jul 2020
Overview of the 2020 epidemic question answering trackTravis R Goodwin, Dina Demner-Fushman, Kyle Lo, Lucy Lu Wang, William R Hersh, HT Dang, and Ian M SoboroffIn Text Analysis Conference, Jul 2020In response to the COVID-19 pandemic, we organized a new track for TAC 2020: Epidemic Question Answering (EPIC-QA). This track challenges teams to develop systems capable of automatically answering ad-hoc questions about the disease COVID-19, its causal virus SARS-CoV-2, related coronaviruses, and the recommended response to the pandemic. While COVID-19 has been an impetus for a large body of emergent scientific research and inquiry, the response to COVID-19 raises questions for consumers. The rapid increase in coronavirus literature and evolving guidelines on community response creates a challenging burden not only for the scientific and medical communities but also the general public to stay up-to-date on the latest developments. Consequently, the goal of the track is to evaluate systems on their ability to provide timely and accurate expert-level answers as expected by the scientific and medical communities as well as answers in consumer-friendly language for the general public.
@inproceedings{Goodwin2020OverviewOf, author = {Goodwin, Travis R and Demner-Fushman, Dina and Lo, Kyle and Wang, Lucy Lu and Hersh, William R and Dang, HT and Soboroff, Ian M}, booktitle = {Text Analysis Conference}, needs_review = {true}, title = {Overview of the 2020 epidemic question answering track}, url = {https://tac.nist.gov/publications/2020/additional.papers/TAC2020.EPIC-QA.overview.notebook.pdf}, year = {2020} }










2019
-
 SciBERT: A Pretrained Language Model for Scientific TextIz Beltagy, Kyle Lo, and Arman CohanIn EMNLP, Nov 2019
SciBERT: A Pretrained Language Model for Scientific TextIz Beltagy, Kyle Lo, and Arman CohanIn EMNLP, Nov 2019Obtaining large-scale annotated data for NLP tasks in the scientific domain is challenging and expensive. We release SciBERT, a pretrained language model based on BERT (Devlin et. al., 2018) to address the lack of high-quality, large-scale labeled scientific data. SciBERT leverages unsupervised pretraining on a large multi-domain corpus of scientific publications to improve performance on downstream scientific NLP tasks. We evaluate on a suite of tasks including sequence tagging, sentence classification and dependency parsing, with datasets from a variety of scientific domains. We demonstrate statistically significant improvements over BERT and achieve new state-of-the-art results on several of these tasks. The code and pretrained models are available at https://github.com/allenai/scibert/.
@inproceedings{Beltagy2019ScibertPretrainedLanguage, author = {Beltagy, Iz and Lo, Kyle and Cohan, Arman}, booktitle = {EMNLP}, doi = {10.18653/v1/D19-1371}, month = nov, title = {{S}ci{BERT}: A Pretrained Language Model for Scientific Text}, url = {https://aclanthology.org/D19-1371}, year = {2019} } -
 Quantifying Sex Bias in Clinical Studies at Scale With Automated Data ExtractionSergey Feldman, Waleed Ammar, Kyle Lo, Elly Trepman, Madeleine Zuylen, and Oren EtzioniJAMA Network Open, Jul 2019
Quantifying Sex Bias in Clinical Studies at Scale With Automated Data ExtractionSergey Feldman, Waleed Ammar, Kyle Lo, Elly Trepman, Madeleine Zuylen, and Oren EtzioniJAMA Network Open, Jul 2019Analyses of female representation in clinical studies have been limited in scope and scale.To perform a large-scale analysis of global enrollment sex bias in clinical studies.In this cross-sectional study, clinical studies from published articles from PubMed from 1966 to 2018 and records from Aggregate Analysis of ClinicalTrials.gov from 1999 to 2018 were identified. Global disease prevalence was determined for male and female patients in 11 disease categories from the Global Burden of Disease database: cardiovascular, diabetes, digestive, hepatitis (types A, B, C, and E), HIV/AIDS, kidney (chronic), mental, musculoskeletal, neoplasms, neurological, and respiratory (chronic). Machine reading algorithms were developed that extracted sex data from tables in articles and records on December 31, 2018, at an artificial intelligence research institute. Male and female participants in 43 135 articles (792 004 915 participants) and 13 165 records (12 977 103 participants) were included.Sex bias was defined as the difference between the fraction of female participants in study participants minus prevalence fraction of female participants for each disease category. A total of 1000 bootstrap estimates of sex bias were computed by resampling individual studies with replacement. Sex bias was reported as mean and 95\% bootstrap confidence intervals from articles and records in each disease category over time (before or during 1993 to 2018), with studies or participants as the measurement unit.There were 792 004 915 participants, including 390 470 834 female participants (49\%), in articles and 12 977 103 participants, including 6 351 619 female participants (49\%), in records. With studies as measurement unit, substantial female underrepresentation (sex bias ≤ −0.05) was observed in 7 of 11 disease categories, especially HIV/AIDS (mean for articles, −0.17 [95\% CI, −0.18 to −0.16]), chronic kidney diseases (mean, −0.17 [95\% CI, −0.17 to −0.16]), and cardiovascular diseases (mean, −0.14 [95\% CI, −0.14 to −0.13]). Sex bias in articles for all categories combined was unchanged over time with studies as measurement unit (range, −0.15 [95\% CI, −0.16 to −0.13] to −0.10 [95\% CI, −0.14 to −0.06]), but improved from before or during 1993 (mean, −0.11 [95\% CI, −0.16 to −0.05]) to 2014 to 2018 (mean, −0.05 [95\% CI, −0.09 to −0.02]) with participants as the measurement unit. Larger study size was associated with greater female representation.Automated extraction of the number of participants in clinical reports provides an effective alternative to manual analysis of demographic bias. Despite legal and policy initiatives to increase female representation, sex bias against female participants in clinical studies persists. Studies with more participants have greater female representation. Differences between sex bias estimates with studies vs participants as measurement unit, and between articles vs records, suggest that sex bias with both measures and data sources should be reported.
@article{Feldman2019QuantifyingSexBias, author = {Feldman, Sergey and Ammar, Waleed and Lo, Kyle and Trepman, Elly and van Zuylen, Madeleine and Etzioni, Oren}, doi = {10.1001/jamanetworkopen.2019.6700}, journal = {JAMA Network Open}, month = jul, title = {{Quantifying Sex Bias in Clinical Studies at Scale With Automated Data Extraction}}, url = {https://doi.org/10.1001/jamanetworkopen.2019.6700}, volume = {2}, year = {2019} } -
 Combining Distant and Direct Supervision for Neural Relation ExtractionIz Beltagy, Kyle Lo, and Waleed AmmarIn NAACL, Jun 2019
Combining Distant and Direct Supervision for Neural Relation ExtractionIz Beltagy, Kyle Lo, and Waleed AmmarIn NAACL, Jun 2019In relation extraction with distant supervision, noisy labels make it difficult to train quality models. Previous neural models addressed this problem using an attention mechanism that attends to sentences that are likely to express the relations. We improve such models by combining the distant supervision data with an additional directly-supervised data, which we use as supervision for the attention weights. We find that joint training on both types of supervision leads to a better model because it improves the model’s ability to identify noisy sentences. In addition, we find that sigmoidal attention weights with max pooling achieves better performance over the commonly used weighted average attention in this setup. Our proposed method achieves a new state-of-the-art result on the widely used FB-NYT dataset.
@inproceedings{Beltagy2019CombiningDistantDirect, author = {Beltagy, Iz and Lo, Kyle and Ammar, Waleed}, booktitle = {NAACL}, doi = {10.18653/v1/N19-1184}, month = jun, title = {Combining Distant and Direct Supervision for Neural Relation Extraction}, url = {https://aclanthology.org/N19-1184}, year = {2019} }



2018
-
 Ontology alignment in the biomedical domain using entity definitions and contextLucy Lu Wang, Chandra Bhagavatula, Mark Neumann, Kyle Lo, Chris Wilhelm, and Waleed AmmarIn BioNLP Workshop, Jul 2018
Ontology alignment in the biomedical domain using entity definitions and contextLucy Lu Wang, Chandra Bhagavatula, Mark Neumann, Kyle Lo, Chris Wilhelm, and Waleed AmmarIn BioNLP Workshop, Jul 2018Ontology alignment is the task of identifying semantically equivalent entities from two given ontologies. Different ontologies have different representations of the same entity, resulting in a need to de-duplicate entities when merging ontologies. We propose a method for enriching entities in an ontology with external definition and context information, and use this additional information for ontology alignment. We develop a neural architecture capable of encoding the additional information when available, and show that the addition of external data results in an F1-score of 0.69 on the Ontology Alignment Evaluation Initiative (OAEI) largebio SNOMED-NCI subtask, comparable with the entity-level matchers in a SOTA system.
@inproceedings{Wang2018OntologyAlignmentBiomedical, author = {Wang, Lucy Lu and Bhagavatula, Chandra and Neumann, Mark and Lo, Kyle and Wilhelm, Chris and Ammar, Waleed}, booktitle = {BioNLP Workshop}, doi = {10.18653/v1/W18-2306}, month = jul, title = {Ontology alignment in the biomedical domain using entity definitions and context}, url = {https://aclanthology.org/W18-2306}, year = {2018} } -
 Construction of the Literature Graph in Semantic ScholarWaleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Crawford, Doug Downey, Jason Dunkelberger, and 16 more authorsIn NAACL, Jun 2018
Construction of the Literature Graph in Semantic ScholarWaleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Crawford, Doug Downey, Jason Dunkelberger, and 16 more authorsIn NAACL, Jun 2018We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in \urlwww.semanticscholar.org.
@inproceedings{Ammar2018ConstructionLiteratureGraph, author = {Ammar, Waleed and Groeneveld, Dirk and Bhagavatula, Chandra and Beltagy, Iz and Crawford, Miles and Downey, Doug and Dunkelberger, Jason and Elgohary, Ahmed and Feldman, Sergey and Ha, Vu and Kinney, Rodney and Kohlmeier, Sebastian and Lo, Kyle and Murray, Tyler and Ooi, Hsu-Han and Peters, Matthew and Power, Joanna and Skjonsberg, Sam and Wang, Lucy Lu and Wilhelm, Chris and Yuan, Zheng and van Zuylen, Madeleine and Etzioni, Oren}, booktitle = {NAACL}, doi = {10.18653/v1/N18-3011}, month = jun, title = {Construction of the Literature Graph in Semantic Scholar}, url = {https://aclanthology.org/N18-3011}, year = {2018} } -
 Citation count analysis for papers with preprintsSergey Feldman, Kyle Lo, and Waleed AmmarArXiv, May 2018
Citation count analysis for papers with preprintsSergey Feldman, Kyle Lo, and Waleed AmmarArXiv, May 2018We explore the degree to which papers prepublished on arXiv garner more citations, in an attempt to paint a sharper picture of fairness issues related to prepublishing. A paper’s citation count is estimated using a negative-binomial generalized linear model (GLM) while observing a binary variable which indicates whether the paper has been prepublished. We control for author influence (via the authors’ h-index at the time of paper writing), publication venue, and overall time that paper has been available on arXiv. Our analysis only includes papers that were eventually accepted for publication at top-tier CS conferences, and were posted on arXiv either before or after the acceptance notification. We observe that papers submitted to arXiv before acceptance have, on average, 65% more citations in the following year compared to papers submitted after. We note that this finding is not causal, and discuss possible next steps.
@article{Feldman2018CitationCountAnalysis, author = {Feldman, Sergey and Lo, Kyle and Ammar, Waleed}, journal = {ArXiv}, month = may, title = {Citation count analysis for papers with preprints}, url = {https://arxiv.org/abs/1805.05238}, volume = {1805.05238}, year = {2018} }


